restructure query so it avoids ORs
It appears postgres is picking suboptimal indexes if too many ORs exist
despite how trivial the condition is.
This bypasses conditional in the query and evals them upfront.
On meta for my user this made a 10x perf difference.
This boils down to either having `OR u.admin` or not having `OR u.admin` in
the query.
Note, to avoid race conditions we are setting last_unread to 10 minutes ago
if there is nothing unread.
This is safer in case of in progress transactions
we don't want to lose unread for any window of time.
This optimisation avoids large scans joining the topics table with the
topic_users table.
Previously when a user carried a lot of read state we would have to join
the entire read state with the topics table. This operation would slow down
home page and every topic page. The more read state you accumulated the
larger the impact.
The optimisation helps people who clean up unread, however if you carry
unread from years ago it will only have minimal impact.
Sometimes sidekiq is so fast that it starts jobs before transactions
have comitted. This patch moves the message bus stuff until after things
have comitted.
"Rejecting" a user in the queue is equivalent to deleting them, which
would then making it impossible to review rejected users. Now we store
information about the user in the payload so if they are deleted things
still display in the Rejected view.
Secondly, if a user is destroyed outside of the review queue, it will
now automatically "Reject" that queue item.
Conversely, if a user is deactivated the reviewable should automatically
be rejected.
Before this fix, if a user was not active they'd still show in the
review queue but without an "Approve" button which was confusing.
Previously every rebake would remove and recreate records in this table
This caused created_at and updated_at to keep changing
Yes, I know the SQL is somewhat complex, but this makes quote extraction
more efficient cause we do everything in 2 round trips.
This also removes some concurrency protection we should no longer need
Some sites have external URLs that don't even match `%/uploads/%' and
some sites surprise me with URLs that contains the default path when it
is a site in a multisite cluster. We can't do anything about those.
Adds the parallel_tests gem, and redis/postgres configuration for running rspec tests in parallel. To use:
```
rake parallel:rake[db:create]
rake parallel:rake[db:migrate]
rake parallel:spec
```
This brings the test suite from 12m20s to 3m11s on my macOS machine
This commit fixes the follow quality issue with `PostSearchData#raw_data`:
1. URLs are being tokenized and links with similar href and characters
are being duplicated in the raw data.
`Post#cooked`:
```
<p><a href=\"https://meta.discourse.org/some.png\" class=\"onebox\" target=\"_blank\" rel=\"nofollow noopener\">https://meta.discourse.org/some.png</a></p>
```
`PostSearchData#raw_data` Before:
```
This is a test topic 0 Uncategorized https://meta.discourse.org/some.png discourse org/some png https://meta.discourse.org/some.png discourse org/some png
```
`PostSearchData#raw_data` After:
```
This is a test topic 0 Uncategorized https://meta.discourse.org/some.png meta discourse org
```
2. Ligthbox being included in search pollutes the
`PostSearchData#raw_data` unncessarily.
From 28 March 2018 to 28 March 2019, searches for the term `image` on
`meta.discourse.org` had a click through rate of 2.1%. Non-lightboxed images are not included in indexing for search yet we were indexing content within a lightbox. Also, search for terms like `image` was affected we were using `Pasted image` as the filename for
uploads that were pasted.
`Post#cooked`
```
<p>Let me see how I can fix this image<br>\n<div class=\"lightbox-wrapper\"><a class=\"lightbox\" href=\"https://meta.discourse.org/some.png\" title=\"some.png\" rel=\"nofollow noopener\"><img src=\"https://meta.discourse.org/some.png\" width=\"275\" height=\"299\"><div class=\"meta\">\n<svg class=\"fa d-icon d-icon-far-image svg-icon\" aria-hidden=\"true\"><use xlink:href=\"#far-image\"></use></svg><span class=\"filename\">some.png</span><span class=\"informations\">1750×2000</span><svg class=\"fa d-icon d-icon-discourse-expand svg-icon\" aria-hidden=\"true\"><use xlink:href=\"#discourse-expand\"></use></svg>\n</div></a></div></p>
```
`PostSearchData#raw_data` Before:
```
This is a test topic 0 Uncategorized Let me see how I can fix this image some.png png https://meta.discourse.org/some.png discourse org/some png some.png png 1750×2000
```
`PostSearchData#raw_data` After:
```
This is a test topic 0 Uncategorized Let me see how I can fix this image
```
In terms of indexing performance, we now have to parse the given HTML
through nokogiri twice. However performance is not a huge worry here since a string length of 194170 takes only 30ms
to scrub plus the indexing takes place in a background job.
Includes support for flags, reviewable users and queued posts, with REST API
backwards compatibility.
Co-Authored-By: romanrizzi <romanalejandro@gmail.com>
Co-Authored-By: jjaffeux <j.jaffeux@gmail.com>
- s3_force_path_style was added as a Minio specific url scheme but it has never been well supported in our code base.
- Our new migrate_to_s3 rake task does not work reliably with path style urls too
- Minio has also added support for virtual style requests i.e the same scheme as AWS S3/DO Spaces so we can rely on that instead of using path style requests.
- Add migration to drop s3_force_path_style from the site_settings table
* improved emoji support
- always optimize images as part of the task
- use the unicode standard ordering/naming for sections
* UX: more height for when there are recently used
Migrates email user options to a new data structure, where `email_always`, `email_direct` and `email_private_messages` are replace by
* `email_messages_level`, with options: `always`, `only_when_away` and `never` (defaults to `always`)
* `email_level`, with options: `always`, `only_when_away` and `never` (defaults to `only_when_away`)
* FEATURE: Exposing a way to add a generic report filter
## Why do we need this change?
Part of the work discussed [here](https://meta.discourse.org/t/gain-understanding-of-file-uploads-usage/104994), and implemented a first spike [here](https://github.com/discourse/discourse/pull/6809), I am trying to expose a single generic filter selector per report.
## How does this work?
We basically expose a simple, single generic filter that is computed and displayed based on backend values passed into the report.
This would be a simple contract between the frontend and the backend.
**Backend changes:** we simply need to return a list of dropdown / select options, and enable the report's newly introduced `custom_filtering` property.
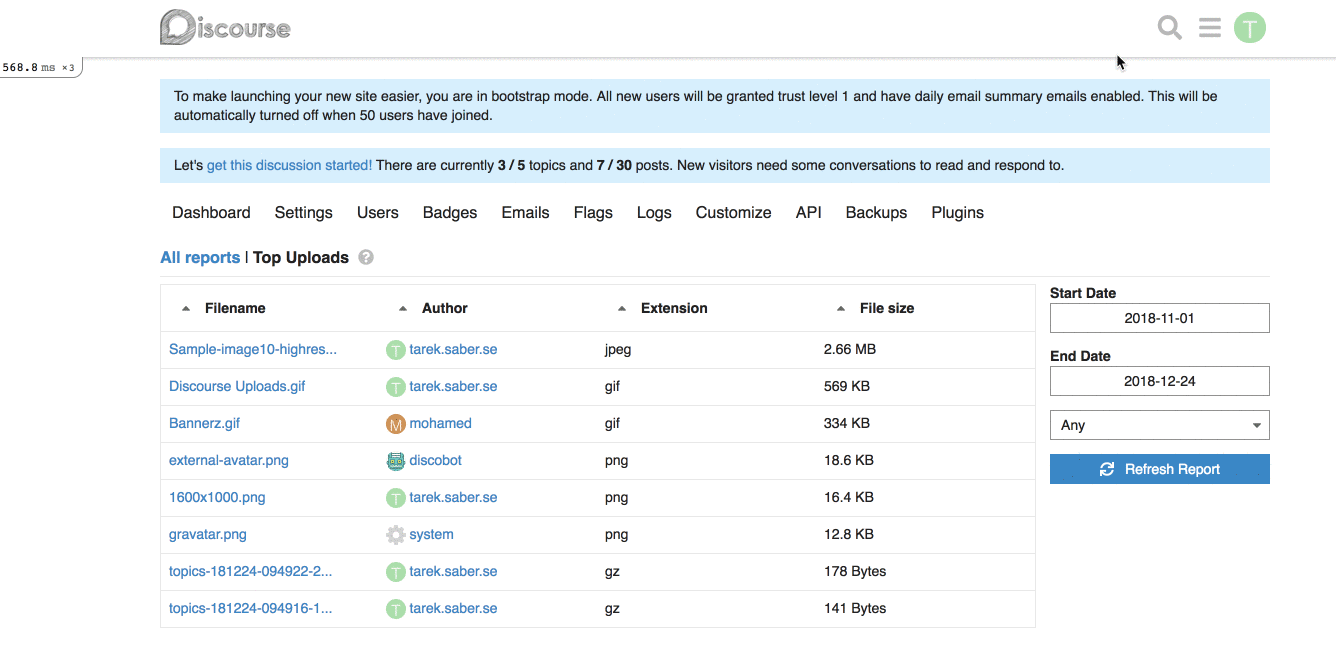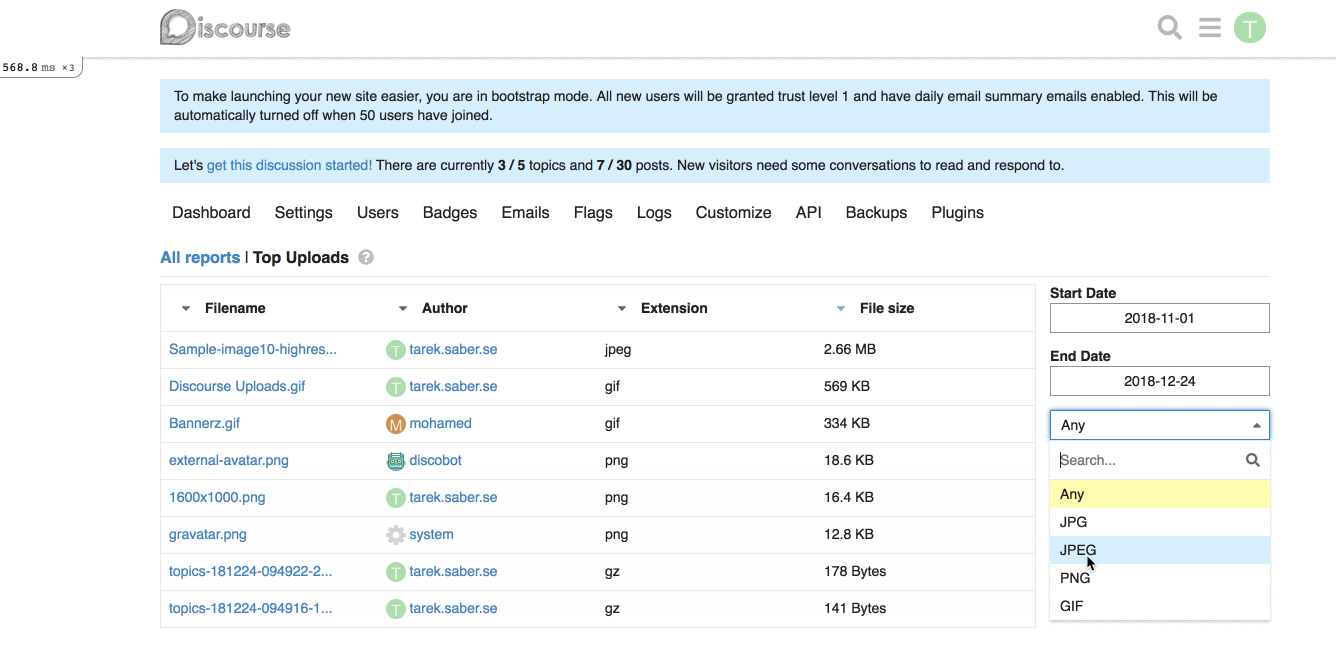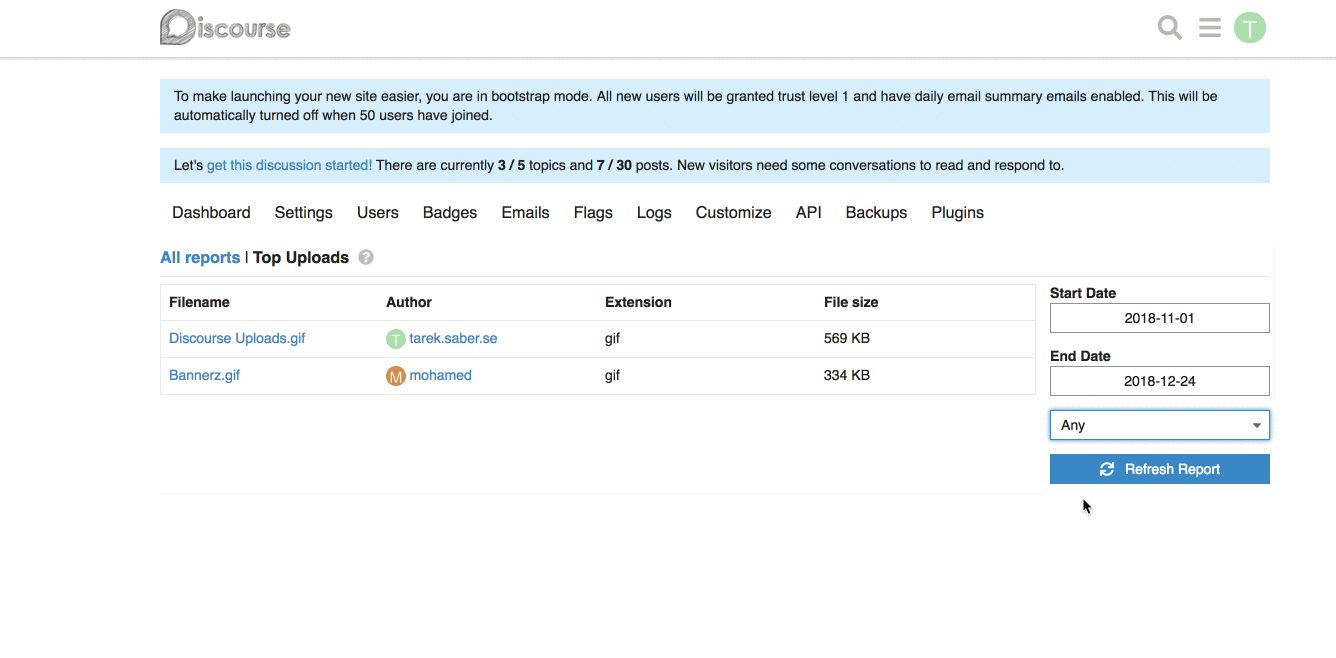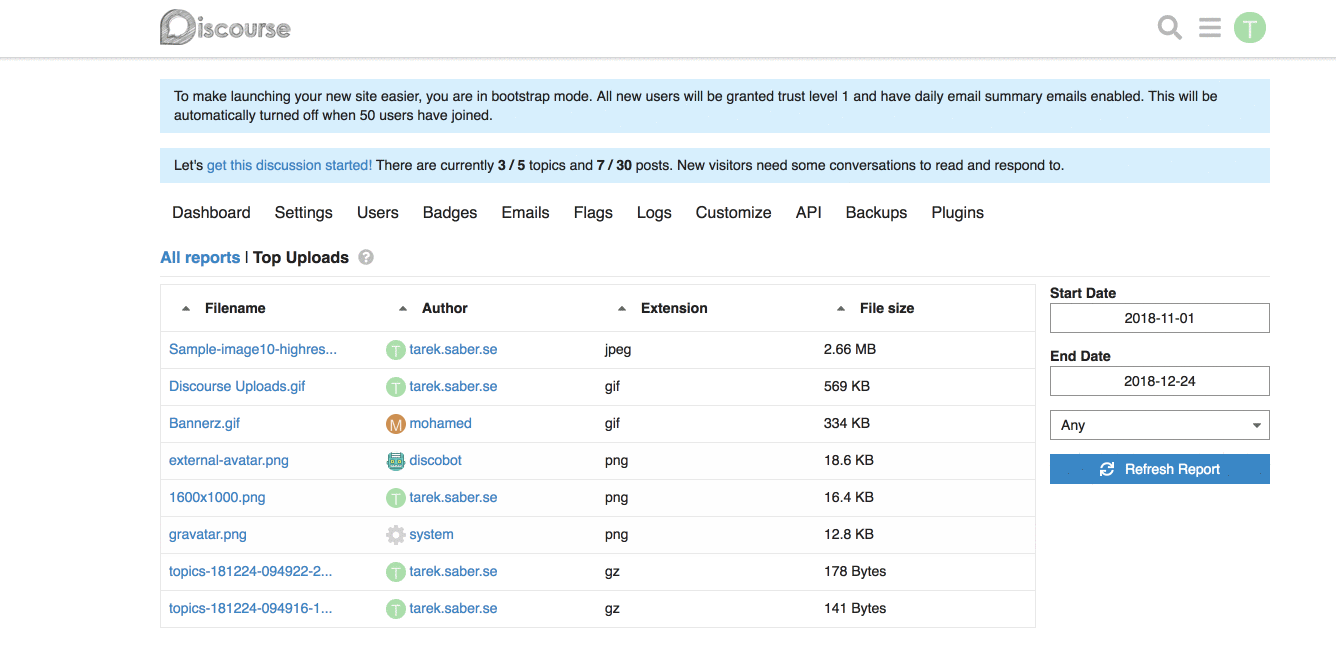
For example, for our [Top Uploads](https://github.com/discourse/discourse/pull/6809/files#diff-3f97cbb8726f3310e0b0c386dbe89e22R1423) report, it can look like this on the backend:
```ruby
report.custom_filtering = true
report.custom_filter_options = [{ id: "any", name: "Any" }, { id: "jpg", name: "JPEG" } ]
```
In our javascript report HTTP call, it will look like:
```js
{
"custom_filtering": true,
"custom_filter_options": [
{
"id": "any",
"name": "Any"
},
{
"id": "jpg",
"name": "JPG"
}
]
}
```
**Frontend changes:** We introduced a generic `filter` param and a `combo-box` which hooks up into the existing framework for fetching a report.
This works alright, with the limitation of being a single custom filter per report. If we wanted to add, for an instance a `filesize filter`, this will not work for us. _I went through with this approach because it is hard to predict and build abstractions for requirements or problems we don't have yet, or might not have._
## How does it look like?
## More on the bigger picture
The major concern here I have is the solution I introduced might serve the `think small` version of the reporting work, but I don't think it serves the `think big`, I will try to shed some light into why.
Within the current design, It is hard to maintain QueryParams for dynamically generated params (based on the idea of introducing more than one custom filter per report).
To allow ourselves to have more than one generic filter, we will need to:
a. Use the Route's model to retrieve the report's payload (we are now dependent on changes of the QueryParams via computed properties)
b. After retrieving the payload, we can use the `setupController` to define our dynamic QueryParams based on the custom filters definitions we received from the backend
c. Load a custom filter specific Ember component based on the definitions we received from the backend
* First take
* Add support for sprites in themes
Automatically register any custom icons added via themes or plugins
* Fix theme sprite caching
* Simplify test
* Update lib/svg_sprite/svg_sprite.rb
Co-Authored-By: pmusaraj <pmusaraj@gmail.com>
* Fix /svg-sprite/search request
* FEATURE: Add `Top Ignored Users` report
## Why?
This is part of the [Ability to ignore a user feature](https://meta.discourse.org/t/ability-to-ignore-a-user/110254/8), and also part of [this PR](https://github.com/discourse/discourse/pull/7144).
We want to send a System Message daily when a specific count threshold for an ignored is reached. To make this system message informative, we want to link to a report for the Top Ignored Users too.
- Notices are visible only by poster and trust level 2+ users.
- Notices are not generated for non-human or staged users.
- Notices are deleted when post is deleted.
It seems that due to jobs being asynchronous and wrapping code in a
DistributedMutex that by the time we run the
`UserAvatar#update_gravatar!` job that the user/user email might be
destroyed.
This patch checks before a call to `user.email_hash` to make sure
the user and primary email exist to prevent the exception. If not
present, the job exits as there's nothing to do because we are
probably running after the user was destroyed for some reason.
Mods require visibility to everyone group cause category dialogs need to
know about this.
If the site setting `allow moderators to create categories` will not function
without this
Note there is no security expansion of rights here, the group is technically
empty anyway and it always looks exactly the same on all discourse instances
Following this change when a user hits `@` and is replying to a topic they
will see usernames of people who were last seen and participated in the topic
This is somewhat experimental, we may tweak this, or make it optional.
Also, a regression in a423a938 where hitting TAB would eat a post you were writing:
Eg this would eat a post:
``` text
@hello, testing 123 <tab>
```
If a theme setting contained invalid SCSS, it would cause an error 500 on the site, with no way to recover. This commit stops loading theme settings in the core stylesheets, and instead only loads the color scheme variables. This change also makes `common/foundation/variables.scss` available to themes without an explicit import.
Treating TIFF and BMP as images cause us to add them to IMG tags, this is very inconsistent across browsers.
You can still upload these files they will simply not be displayed in IMG tags.
Previously it would unhide their post but leave them silenced.
This fix also cleans up some of the helper classes to make it easier
to pass extra data to the silencing code (for example, a link to the
post that caused the user to be silenced.)
This patch also refactors the auto_silence specs to avoid using
stubs.
Currently the theme is matched by name, which can be fragile when there are many themes with the same name. This functionality will be used by the next version of theme CLI.
This does not serve any technical purpose. It is there to provide a signpost for any user/developer that wants to know what to do with a theme archive.
New `about.json` fields (all optional):
- `authors`: An arbitrary string describing the theme authors
- `theme_version`: An arbitrary string describing the theme version
- `minimum_discourse_version`: Theme will be auto-disabled for lower versions. Must be a valid version descriptor.
- `maximum_discourse_version`: Theme will be auto-disabled for lower versions. Must be a valid version descriptor.
A localized description for a theme can be provided in the language files under the `theme_metadata.description` key
The admin UI has been re-arranged to display this new information, and give more prominence to the remote theme options.
Some badges always appeared in the "Other" group (the default group) and some badges were always moved back into the original group during seeding.
Now badges are either in the correct, seeded group or stay in a custom group if the admin moved the badge into a custom group.
This issue is caused by the filename restrictions in `OptimizedImage#ensure_safe_paths!`. Difficult to add a test for this because image optimization is bypassed in test mode.
- Themes can supply translation files in a format like `/locales/{locale}.yml`. These files should be valid YAML, with a single top level key equal to the locale being defined. For now these can only be defined using the `discourse_theme` CLI, importing a `.tar.gz`, or from a GIT repository.
- Fallback is handled on a global level (if the locale is not defined in the theme), as well as on individual keys (if some keys are missing from the selected interface language).
- Administrators can override individual keys on a per-theme basis in the /admin/customize/themes user interface.
- Theme developers should access defined translations using the new theme prefix variables:
JavaScript: `I18n.t(themePrefix("my_translation_key"))`
Handlebars: `{{theme-i18n "my_translation_key"}}` or `{{i18n (theme-prefix "my_translation_key")}}`
- To design for backwards compatibility, theme developers can check for the presence of the `themePrefix` variable in JavaScript
- As part of this, the old `{{themeSetting.setting_name}}` syntax is deprecated in favour of `{{theme-setting "setting_name"}}`
This commit introduces an ultra low priority queue for post rebakes. This
way rebakes can never interfere with regular sidekiq processing for cases
where we perform a large scale rebake.
Additionally it allows Post.rebake_old to be run with rate_limiter: false
to avoid triggering the limiter when rebaking. This is handy for cases
where you want to just force the full rebake and not wait for it to trickle
This corrects 2 issues:
First is a regression with d7c08e21 for some reason dependent :delete_all
respects default scopes where-as dependent :destroy bypasses it.
Secondly, we were keeping orphan user actions around on user destroy, this
ensures we remove all the user actions not only ones that originated by
the user.
So for example: if I like a post of user A we create a user action saying I
did that, but once user A is deleted we were not removing the action leading
to an orphan action in the database.
Users can have 100s of thousands of post and user actions, we do not want
to destroy each individually cause the tracking is enormous and the amount
of queries we would need is enormous.
This gives up on the `after_commit` hook on `post_actions` which ships a message
to clients to synchronize a post, so some phantom post_actions may remain
in the UX in the rare occasion we delete a user. The phantoms will be gone
on reload.
This should only change the order on freshly imported instances with no likes.
This makes the user summary show the latest topics/posts/links instead of the firsts until the users get some likes.
This allows us to run regular rebakes without starving the normal queue.
It additionally adds the ability to specify queue with `Jobs.enqueue` so
we can specifically queue a job with lower priority using the `queue` arg.
Before this patch, a high trust level user could flag something
and have an action be taken, as well as skipping the flag queue.
Now, if a TL3/TL4 cause an action, the flag will skip the minimum
visibility check and allow staff to review it.
FIX: buildTranslationTree was erroring when translations overlapped (ie. ":-)" and ":-))")
FIX: emoji translations wasn't working properly when translations overlapped
Previously we only allowed one image optimization per machine, this meant there
was cross talk between avatar resizing and Sidekiq. This could lead to large
amounts of starvation when optimized image version changed which in turn could
block the Sidekiq queue.
This increases amount of allowed load on machines but this is preferable to
having crosstalk between avatar resizing and Sidekiq.
Some cloud providers (Google Memorystore) do not support any CLIENT commands
By setting :id to nil in the redis config hash we can avoid these commands.
This adds a special global setting GCE users can enable:
`DISCOURSE_REDIS_SKIP_CLIENT_COMMANDS = true`
We have the periodical job that regularly will rebake old posts. This is
used to trickle in update to cooked markdown. The problem is that each rebake
can issue multiple background jobs (post process and pull hotlinked images)
Previously we had no per-cluster limit so cluster running 100s of sites could
flood the sidekiq queue with rebake related jobs.
New system introduces a hard limit of 300 rebakes per 15 minutes across a
cluster to ensure the sidekiq job is not dominated by this.
We also reduced `rebake_old_posts_count` to 80, which is a safer default.
This reverts commit 993f847a2c.
There is an edge case where the link click redirect fails when the URL has trailing slash. Need to figure out a better fix for this.
Previously we had no idea what algorithm generated thumbnails, this starts tracking the version.
We also bumped up the version to force all optimized images to be generated. This is important cause we recently introduced pngquant which results in much smaller images.
This feature ensures optimized images run via pngquant, this results extreme amounts of savings for resized images. Effectively the only impact is that the color palette on small resized images is reduced to 256.
To ensure safety we only apply this optimisation to images smaller than 500k.
This commit also makes a bunch of image specs less fragile.
Previously if upload had missing width and height we would calculate
on first use BUT we (me) forgot to save this to the database
This was particularly bad on home page cause category images (when old)
miss dimensions.
This generates a 10x10 PNG thumbnail for each lightboxed image.
If Image Lazy Loading is enabled (IntersectionObserver API) then
we'll load the low res version when offscreen. As the image scrolls
in we'll swap it for the high res version.
We use a WeakMap to track the old image attributes. It's much less
memory than storing them as `data-*` attributes and swapping them
back and forth all the time.
* Dashboard doesn't timeout anymore when Amazon S3 is used for backups
* Storage stats are now a proper report with the same caching rules
* Changing the backup_location, s3_backup_bucket or creating and deleting backups removes the report from the cache
* It shows the number of backups and the backup location
* It shows the used space for the correct backup location instead of always showing used space on local storage
* It shows the date of the last backup as relative date
`SiteSerializer#is_readonly` is cached for an anonymous user so we have
to clear the cache when disabling readonly mode. Otherwise, the site may
appear to be in readonly mode for an extended period of time.
Some URLs in browsers are non compliant and contain twos `#` this commit adds
special handling for this edge case by auto encoding any fragments containing `#`
Do not send an activation email to users invited via email. They
already confirmed their email address by clicking the invite link.
Users invited via link will need to confirm their email address before
they can login.
This was an indentation mistake introduced in 44eba0b. Pretty understandable, considering we are indented 8 levels deep in this method. Will follow-up with a refactor to improve this.
Previously we would notify on small actions if they were whispers
this inconsistently lead to all sorts of problems including
- collapsed "N replies" after assign
- empty push notifications
New behavior adds an api to explicitly send push notifications as well
if needed: create_notification_alert
UserStat has some special logic to keep adding time read if repeat calls
are made in intervals less than 100 seconds. This is called regularly
when we update read timings on a topic.
We only need to cache this key in redis for 100 seconds, however previously
we would keep it forever, 1 key per user. This has potential of bloating
a very large amount of keys for no longer active users in redis.
* FEATURE: allow plugins and themes to extend the default CSP
For plugins:
```
extend_content_security_policy(
script_src: ['https://domain.com/script.js', 'https://your-cdn.com/'],
style_src: ['https://domain.com/style.css']
)
```
For themes and components:
```
extend_content_security_policy:
type: list
default: "script_src:https://domain.com/|style_src:https://domain.com"
```
* clear CSP base url before each test
we have a test that stubs `Rails.env.development?` to true
* Only allow extending directives that core includes, for now
Changes to functionality
- Removed syncing of user metadata including gender, location etc.
These are no longer available to standard Facebook applications.
- Removed the remote 'revoke' functionality. No other providers have
it, and it does not appear to be standard practice in other apps.
- The 'facebook_no_email' event is no longer logged. The system can
cope fine with a missing email address.
Data is migrated to the new user_associated_accounts table.
facebook_user_infos can be dropped once we are confident the data has
been migrated successfully.
A generic implementation of Auth::Authenticator which stores data in the
new UserAssociatedAccount model. This should help significantly reduce the duplicated
logic across different auth providers.
* Add missing icons to set
* Revert FA5 revert
This reverts commit 42572ff
* use new SVG syntax in locales
* Noscript page changes (remove login button, center "powered by" footer text)
* Cast wider net for SVG icons in settings
- include any _icon setting for SVG registry (offers better support for plugin settings)
- let themes store multiple pipe-delimited icons in a setting
- also replaces broken onebox image icon with SVG reference in cooked post processor
* interpolate icons in locales
* Fix composer whisper icon alignment
* Add support for stacked icons
* SECURITY: enforce hostname to match discourse hostname
This ensures that the hostname rails uses for various helpers always matches
the Discourse hostname
* load SVG sprite with pre-initializers
* FIX: enable caching on SVG sprites
* PERF: use JSONP for SVG sprites so they are served from CDN
This avoids needing to deal with CORS for loading of the SVG
Note, added the svg- prefix to the filename so we can quickly tell in
dev tools what the file is
* Add missing SVG sprite JSONP script to CSP
* Upgrade to FA 5.5.0
* Add support for all FA4.7 icons
- adds complete frontend and backend for renamed FA4.7 icons
- improves performance of SvgSprite.bundle and SvgSprite.all_icons
* Fix group avatar flair preview
- adds an endpoint at /svg-sprites/search/:keyword
- adds frontend ajax call that pulls icon in avatar flair preview even when it is not in subset
* Remove FA 4.7 font files
* First take on subsetting svg icons
* FontAwesome 5 svg subset WIP
* Include icons from plugins/badges into svg sprite subset
* add svg icon support to themes
* Add spec for SvgSprite
* Misc. SVG icon fixes
* Use FA5 svgs in local-dates plugin
* CSS adjustments, fix SVG icons in group flair
* Use SVG icons in poll plugin
* Add SVG icons to /wizard
We regressed and optimized images no longer worked with svg
The following adds the correct logic to simply copy file for svgs
and bypasses resizing for svg avatars
previously we would ignore socket error, but this would mean that
there could be conditions where we would keep trying to download
gravatars forever (in an hourly job)
Also acquire a transaction per link instead of failing when
any of the links can't be processed.
This prevents ActiveRecord from rolling back the transaction
and the next SQL statement sent to PG will fail. This is
however hard to test as it only happens when there are
two competing process trying to process this method at the
same time.
* FEATURE: add branch option to remote theme import
* FIX: Add missing variable in params
* FIX: Add missing param for import_theme method
* SPEC: Add test methods for branch support in git import
* FIX: Add missing space to scss style
* Do not assume default branch as master
* Change branch field placeholder
* FIX: add missing div start tag
- By default, behaviour is not changed: tags are made lowercase upon creation and edit.
- If force_lowercase_tags is disabled, then mixed case tags are allowed.
- Tags must remain case-insensitively unique. This is enforced by ActiveRecord and Postgres.
- A migration is added to provide a `UNIQUE` index on `lower(name)`. Migration includes a safety to correct any current tags that do not meet the criteria.
- A `where_name` scope is added to `models/tag.rb`, to allow easy case-insensitive lookups. This is used instead of `Tag.where(name: "blah")`.
- URLs remain lowercase. Mixed case URLs are functional, but have the lowercase equivalent as the canonical.
If we detect redis is in readonly we can not correctly get a mutex
raise an exception to notify caller
When getting optimized images avoid the distributed mutex unless
for some reason it is the first call and we need to generate a thumb
In redis readonly no thumbnails will be generated
The intent from day one was to keep MAX_TO_KEEP stylesheets per target
however the DELETE statement did not perform target filtering
This meant we often deleted the wrong stylesheets from the cache
Previously we would raise a 500 error if a moderator tried to agree on a
flag another moderator deferred.
This can happen cause the UX for flags does not live refresh as flags
are handled
For a normal upload url
Before
```
Warming up --------------------------------------
264.000 i/100ms
Calculating -------------------------------------
2.754k (± 8.4%) i/s - 13.728k in 5.022066s
```
After
```
Warming up --------------------------------------
341.000 i/100ms
Calculating -------------------------------------
3.435k (±11.6%) i/s - 17.050k in 5.045676s
```
Use:
locale
locale_force_update
To force user locale on users where SiteSetting.allow_user_locale is enabled
Note: If an invalid locale is specified no action will occur
Previously we used width and height for thumbnails, new code ensures
1. We auto correct width and height
2. We added extra columns for thumbnail_width and height, this is determined
by actual upload and no longer passed in as a side effect
3. Optimized Image now stores filesize which can be used for analysis, decisions
Also
- fixes Android image manifest as a side effect
- fixes issue where a thumbnail generated that is smaller than the upload is no longer used
* FIX: don't allow inviting more than `max_allowed_message_recipients` setting allows
* add specs for guardian
* user preferences for auto track shouldn't be applicable to PMs (it auto watches on visit)
Execlude PMs from "Automatically track topics I enter..." and "When I post in a topic, set that topic to..." user preferences
* groups take only 1 slot in PM
* just return if topic is a PM
In the past the filename of the origin was used as the source
for the extension of the file when optimizing on upload.
We now use the actual calculated extension based on upload data.
At the moment core providers are hard-coded in Javascript, and plugin providers get added to the JS payload at compile time. This refactor means that we only ship enabled providers to the client.
* drafts in user profile: only show to user herself (not to admins), use avatar replying to (instead of topic OP), add keyboard shortcut for drafts, simplify display labels
* use JSON when testing Draft.stream
* add drafts.json endpoint, user profile tab with drafts stream
* improve drafts stream display in user profile
* truncate excerpts in drafts list, better handling for resume draft action
* improve draft stream SQL query, add rspec tests
* if composer is open, quietly close it when user opens another draft from drafts stream; load PM draft only when user is in /u/username/messages (instead of /u/username)
* cleanup
* linting fixes
* apply prettier styling to modified files
* add client tests for drafts, includes a fixture for drafts.json
* improvements to code following review
* refresh drafts route when user deletes a draft open in the composer while being in the drafts route; minor prettier scss fix
* added more spec tests, deleted an acceptance test for removing drafts that was too finicky, formatting and code style fixes, added appEvent for draft:destroyed
* prettier, eslint fixes
* use "username_lower" from users table, added error handling for rejected promises
* adds guardian spec for can_see_drafts, adds improvements following code review
* move DraftsController spec to its own file
* fix failing drafts qunit test, use getOwner instead of deprecated this.container
* limit test fixture for draft.json testing to new_topic request only
Checking `plugin.enabled?` while initializing plugins causes issues in two ways:
- An application restart is required for changes to take effect. A load-balanced multi-server environment could behave very weirdly if containers restart at different times.
- In a multisite environment, it takes the `enabled?` setting from the default site. Changes on that site affect all other sites in the cluster.
Instead, `plugin.enabled?` should be checked at runtime, in the context of a request. This commit removes `plugin.enabled?` from many `instance.rb` methods.
I have added a working `plugin.enabled?` implementation for methods that actually affect security/functionality:
- `post_custom_fields_whitelist`
- `whitelist_staff_user_custom_field`
- `add_permitted_post_create_param`
It was a dropdown to provide choices of color schemes,
and only one scheme could be shown.
With this commit, multiple color scheme previews can be displayed on
one page at the same time, making admins choose color schemes more
easily.
Theme preview windows are shrinked.
Imported default color schemes.
Co-Authored-By: Misaka 0x4e21 <misaka4e21@gmail.com>
- moderation tab
- sorting/pagination
- improved third party reports support
- trending charts
- better perf
- many fixes
- refactoring
- new reports
Co-Authored-By: Simon Cossar <scossar@users.noreply.github.com>
This was not picked up by tests because scheduled jobs are run immediately
and in the current thread (and therefore the current database transaction).
This particular case sometimes occurs inside multiple nested transactions,
so simply moving the offending line outside of the transaction is not enough.
Implemented TransactionHelper, which allows us to use `TransactionHelper.after_commit`
to define code to be run after the current transaction has been committed.
Use this event to filter the list of auto bumped topics.
EG:
on(:filter_auto_bump_topics) do |_category, filters|
filters.push(->(r) { r.where(<<~SQL)
NOT EXISTS(
SELECT 1 FROM topic_custom_fields
WHERE topic_id = topics.id
AND name = 'accepted_answer_post_id'
)
SQL
})
end
- We spread out bumping through the day, if you are bumping
4 topics then a topic will be bumped every 6 hours
- We add a small, bumping action at the bottom of the post to
denote a topic got bumped
### navigate_to_first_post_after_read setting for categories
When enabled on categories logged on users will return to OP after
reading the entire category. (useful for documentation categories)
### num_auto_bump_daily
Set a number of topics that will automatically bump daily on a category.
- Every 15 minutes we will check if any category has this setting
- Categories with the setting are shuffled
- We exclude pinned, closed, category description and archived topics
- Maximum of 1 topic for the list of categories is bumped till limit reached per category
- We always try to bump oldest first
- Limit is elastic using a RateLimiter that ensures that we only bump N per day
Also some minor organisation on category settings
Froze strings on category.rb
* Phase 0 for user-selectable theme components
- Drops `key` column from the `themes` table
- Drops `theme_key` column from the `user_options` table
- Adds `theme_ids` (array of ints default []) column to the `user_options` table and migrates data from `theme_key` to the new column.
- Removes the `default_theme_key` site setting and adds `default_theme_id` instead.
- Replaces `theme_key` cookie with a new one called `theme_ids`
- no longer need Theme.settings_for_client
* Add possibility to add hidden posts with PostCreator
* FEATURE: Create hidden posts for received spam emails
Spamchecker usually have 3 results: HAM, SPAM and PROBABLY_SPAM
SPAM gets usually directly rejected and needs no further handling.
HAM is good message and usually gets passed unmodified.
PROBABLY_SPAM gets an additional header to allow further processing.
This change addes processing capabilities for such headers and marks
new posts created as hidden when received via email.
I know that **Naming is CRITICAL** and that **Refactoring only NOT welcome**.
But since I spotted this (consistent) typo and the change does not affect any
functionality -- I checked the presence of "asscoiated" in the code base, I
guess the first rule trumps the second one.
It also gave me a false pretext to bypass my reluctance to use Google forms and
sign de CLA. Typos hurt the eye.
3 years is a very conservative limit that allows for a very wide buffer
for year-over-year analysis. The max is set to 5 years because that is
the policy listed for logging in hosted Discourse.
Introduce new patterns for direct sql that are safe and fast.
MiniSql is not prone to memory bloat that can happen with direct PG usage.
It also has an extremely fast materializer and very a convenient API
- DB.exec(sql, *params) => runs sql returns row count
- DB.query(sql, *params) => runs sql returns usable objects (not a hash)
- DB.query_hash(sql, *params) => runs sql returns an array of hashes
- DB.query_single(sql, *params) => runs sql and returns a flat one dimensional array
- DB.build(sql) => returns a sql builder
See more at: https://github.com/discourse/mini_sql
This updates tests to use latest rails 5 practice
and updates ALL dependencies that could be updated
Performance testing shows that performance has not regressed
if anything it is marginally faster now.
* It stored only oneboxed "quotes" when [quote] and links to topics or posts were mixed.
* Revising a post didn't add or remove records from the quoted_posts table.
When `s3_bucket="bucket/folder` in discourse.conf, absolute_base_url
was bucket/folder.s3-region.amazonaws.com
These names are bad, but this mirrors the s3_bucket/s3_bucket_name in
S3Store
N.B. that nearby s3_upload_bucket _should_ include the folder
- adds a link to search log
- display a text if log search queries is disabled
- adds link to trust level and user types
- adds a description for eeach report when browsing a report directly
- remove inactive user report and replace with posts
- clean up internals so grouping by week happens on client
- when switching periods old report was not destroyed leading to bugs
- calculate trend based on previous interval ... not previous 30 days
- show percentages for mau/dau
- be more careful about utc date usage
- show uniqu and click through rate on search panel
- publish key of report with report so we only load the correct one
- subscribe earlier in channel in case of concurrency issues
* Feature: Push notifications for Android
Notification config for desktop and mobile are merged.
Desktop notifications stay as they are for desktop views.
If mobile mode, push notifications are enabled.
Added push notification subscriptions in their own table, rather than through
custom fields.
Notification banner prompts appear for both mobile and desktop when enabled.
The methods are still experimental and might change without notice!
You need to add `include DateGroupable` to your model before you can use it like this:
`User.smart_group_by_date("users.created_at", start_date, end_date)`.count
* rename route to dashboard-next
* better scaling of charts for large data sets
* adjust trend position to avoid overlap
* makes sure silenced/suspended is made on real users
* correctly format data when only one data point
* minor refactoring
* When two SSO requests containing the same email in the payload are
sent at the same time, it would sometimes result in two users
being created but one without an email record. Investigations
points to ActiveRecord not generating the right statements but
we have no figured out the reproduction steps yet. We should review
this after upgrading to Rails 5.2.
In some cases add_groups and remove_groups is too much work, some sites
may wish to simply synchronize group membership based on a list.
When sso_overrides_groups is on all not automatic group membership is
sourced from SSO. Note if you omit to specify groups, they will be cleared
out.
Ignores the site setting "find_related_post_with_key" and always tries to honor the `In-Reply-To` and `References` header for emails sent to a group.
The senders email address must be included in the `To` or `CC` header of a previous email sent to the group and the `Message-ID` of that email must be included in the current email's `In-Reply-To` or `References` header.
* `rescue nil` is a really bad pattern to use in our code base.
We should rescue errors that we expect the code to throw and
not rescue everything because we're unsure of what errors the
code would throw. This would reduce the amount of pain we face
when debugging why something isn't working as expexted. I've
been bitten countless of times by errors being swallowed as a
result during debugging sessions.
This feature can be enabled by choosing a destination for the
`shared drafts category` site setting.
* Staff members can create shared drafts, choosing a destination
category for the topic when it is published.
* Shared Drafts can be viewed in their category, or above the
topic list for the destination category where it will end up.
* When the shared draft is ready, it can be published to the
appropriate category by clicking a button on the topic view.
* When published, Drafts change their timestamps to the current
time, and any edits to the original post are removed.
Why? Some edits by staff are not tracked. For example, during the grace
period, or via the flags/silence dialog.
If a staff member is editing someone else's post, it now goes into the
Staff Action Logs so it can be audited by other staff members.
* This looks like we're doing the same thing but
we're debugging a race condition where a user
can be created without an email record. Therefore,
we prefer the more obvious method of assigning an
association.
* In `pg_dump` 10.3+ and 9.5.12+, in
it does a `SELECT pg_catalog.set_config('search_path', '', false)`
which changes the state of the current connection. This is known
to be problematic with Pgbouncer which reuses connections. As such,
we'll always try to connect directly to PG directly during
the backup/restore process.
{kind=link}
{kind=link}