There was a race condition when 2 invites existed for 1 user where in some
cases data from both invites would be used for the redeem. Depending on DB
ordering.
Fix is to delete duplicate invites earlier in the process prior to
`redeem_from_email` being called.
This reduces chances of errors where consumers of strings mutate inputs
and reduces memory usage of the app.
Test suite passes now, but there may be some stuff left, so we will run
a few sites on a branch prior to merging
Before: 6:05
After: 5:42
Featuring topics for `list/categories` is a very expensive operation that
happened each time we created a topic. This introduces a test only bypass
This is a feature that used to be present in discourse-assign but is
much easier to implement in core. It also allows a topic to be assigned
without it claiming for review and vice versa and allows it to work with
category group reviewers.
We found score hard to understand. It is still there behind the scenes
for sorting purposes, but it is no longer shown.
You can now filter by minimum priority (low, med, high) instead of
score.
This removes all uses of both `send` and `public_send` from consumers of
SiteSetting and instead introduces a `get` helper for dynamic lookup
This leads to much cleaner and safer code long term as we are always explicit
to test that a site setting is really there before sending an arbitrary
string to the class
It also removes a couple of risky stubs from the auth provider test
This change shows a notification number besides the flag icon in the
post menu if there is reviewable content associated with the post.
Additionally, if there is pending stuff to review, the icon has a red
background.
We have also removed the list of links below a post with the flag
status. A reviewer is meant to click the number beside the flag icon to
view the flags. As a consequence of losing those links, we've removed
the ability to undo or ignore flags below a post.
Hidden (staff-only) post actions are whisper posts with no content, that
are later transformed by the client into post actions (discourse-assign
uses this).
After careful analysis of large data-sets it became apparent that avg_time
had no impact whatsoever on "best of" topic scoring. Calculating avg_time
was a very costly operation especially on large databases.
We have some longer term plans of introducing other weighting that is read
time based into our scoring for "best of" and "top" topics, but in the
interim to stop a large amount of work that is not achieving any value we
are removing the jobs.
Column removal will follow once we decide on a new replacement metric.
`Upload#url` is more likely and can change from time to time. When it
does changes, we don't want to have to look through multiple tables to
ensure that the URLs are all up to date. Instead, we simply associate
uploads properly to `UserProfile` so that it does not have to replicate
the URLs in the table.
Minor fixes to add Rails 6 support to Discourse, we now will boot
with RAILS_MASTER=1, all specs pass
Only one tiny deprecation left
Largest change was the way ActiveModel:Errors changed interface a
bit but there is a simple backwards compat way of working it
This change automatically resizes icons for various purposes. Admins can now upload `logo` and `logo_small`, and everything else will be auto-generated. Specific icons can still be uploaded separately if required.
## Core
- Adds an SiteIconManager module which manages automatic resizing and fallback
- Icons are looked up in the OptimizedImage table at runtime, and then cached in Redis. If the resized version is missing for some reason, then most icons will fall back to the original files. Some icons (e.g. PWA Manifest) will return `nil` (because an incorrectly sized icon is worse than a missing icon).
- `SiteSetting.site_large_icon_url` will return the optimized version, including any fallback. `SiteSetting.large_icon` continues to return the upload object. This means that (almost) no changes are required in core/plugins to support this new system.
- Icons are resized whenever a relevant site setting is changed, and during post-deploy migrations
## Wizard
- Allows `requiresRefresh` wizard steps to reload data via AJAX instead of a full page reload
- Add placeholders to the **icons** step of the wizard, which automatically update from the "Square Logo"
- Various copy updates to support the changes
- Remove the "upload-time" resizing for `large_icon`. This is no longer required.
## Site Settings UX
- Move logo/icon settings under a new "Branding" tab
- Various copy changes to support the changes
- Adds placeholder support to the `image-uploader` component
- Automatically reloads site settings after saving. This allows setting placeholders to change based on changes to other settings
- Upload site settings will be assigned a placeholder if SiteIconManager `responds_to?` an icon of the same name
## Dashboard Warnings
- Remove PWA icon and PWA title warnings. Both are now handled automatically.
## Bonus
- Updated the sketch logos to use @awesomerobot's new high-res designs
On busy sites, concurrent requests to insert into post_timings can
occur, which was dealt with using Ruby exceptions.
This moves the handling to PostgreSQL which makes it a bit faster,
and prevents a spam of ERROR in the database logs.
If a tag group is set to only be visible to staff, and is restricted
to a category that is visible by everyone, the tags in the group were
being shown on the /tags page. They weren't visible anywhere else.
This commit fixes it so they don't show on the /tags page.
This is for backwards compatibility purposes. Even if `Upload#url` has a
format that we don't recognize, we should still return the upload object
as long as the upload record is present.
If you turn it on now, default all users to approved since they were
previously. Also support approving a user that doesn't have a reviewable
record (it will be created first.)
This also includes a refactor to move class method calls to
`DiscourseEvent` into an initializer. Otherwise the load order of
classes makes a difference in the test environment and some settings
might be triggered and others not, randomly.
Theme developers can include any number of scss files within the /scss/ directory of a theme. These can then be imported from the main common/desktop/mobile scss.
restructure query so it avoids ORs
It appears postgres is picking suboptimal indexes if too many ORs exist
despite how trivial the condition is.
This bypasses conditional in the query and evals them upfront.
On meta for my user this made a 10x perf difference.
This boils down to either having `OR u.admin` or not having `OR u.admin` in
the query.
Note, to avoid race conditions we are setting last_unread to 10 minutes ago
if there is nothing unread.
This is safer in case of in progress transactions
we don't want to lose unread for any window of time.
This optimisation avoids large scans joining the topics table with the
topic_users table.
Previously when a user carried a lot of read state we would have to join
the entire read state with the topics table. This operation would slow down
home page and every topic page. The more read state you accumulated the
larger the impact.
The optimisation helps people who clean up unread, however if you carry
unread from years ago it will only have minimal impact.
Sometimes sidekiq is so fast that it starts jobs before transactions
have comitted. This patch moves the message bus stuff until after things
have comitted.
"Rejecting" a user in the queue is equivalent to deleting them, which
would then making it impossible to review rejected users. Now we store
information about the user in the payload so if they are deleted things
still display in the Rejected view.
Secondly, if a user is destroyed outside of the review queue, it will
now automatically "Reject" that queue item.
Conversely, if a user is deactivated the reviewable should automatically
be rejected.
Before this fix, if a user was not active they'd still show in the
review queue but without an "Approve" button which was confusing.
Previously every rebake would remove and recreate records in this table
This caused created_at and updated_at to keep changing
Yes, I know the SQL is somewhat complex, but this makes quote extraction
more efficient cause we do everything in 2 round trips.
This also removes some concurrency protection we should no longer need
Some sites have external URLs that don't even match `%/uploads/%' and
some sites surprise me with URLs that contains the default path when it
is a site in a multisite cluster. We can't do anything about those.
Adds the parallel_tests gem, and redis/postgres configuration for running rspec tests in parallel. To use:
```
rake parallel:rake[db:create]
rake parallel:rake[db:migrate]
rake parallel:spec
```
This brings the test suite from 12m20s to 3m11s on my macOS machine
This commit fixes the follow quality issue with `PostSearchData#raw_data`:
1. URLs are being tokenized and links with similar href and characters
are being duplicated in the raw data.
`Post#cooked`:
```
<p><a href=\"https://meta.discourse.org/some.png\" class=\"onebox\" target=\"_blank\" rel=\"nofollow noopener\">https://meta.discourse.org/some.png</a></p>
```
`PostSearchData#raw_data` Before:
```
This is a test topic 0 Uncategorized https://meta.discourse.org/some.png discourse org/some png https://meta.discourse.org/some.png discourse org/some png
```
`PostSearchData#raw_data` After:
```
This is a test topic 0 Uncategorized https://meta.discourse.org/some.png meta discourse org
```
2. Ligthbox being included in search pollutes the
`PostSearchData#raw_data` unncessarily.
From 28 March 2018 to 28 March 2019, searches for the term `image` on
`meta.discourse.org` had a click through rate of 2.1%. Non-lightboxed images are not included in indexing for search yet we were indexing content within a lightbox. Also, search for terms like `image` was affected we were using `Pasted image` as the filename for
uploads that were pasted.
`Post#cooked`
```
<p>Let me see how I can fix this image<br>\n<div class=\"lightbox-wrapper\"><a class=\"lightbox\" href=\"https://meta.discourse.org/some.png\" title=\"some.png\" rel=\"nofollow noopener\"><img src=\"https://meta.discourse.org/some.png\" width=\"275\" height=\"299\"><div class=\"meta\">\n<svg class=\"fa d-icon d-icon-far-image svg-icon\" aria-hidden=\"true\"><use xlink:href=\"#far-image\"></use></svg><span class=\"filename\">some.png</span><span class=\"informations\">1750×2000</span><svg class=\"fa d-icon d-icon-discourse-expand svg-icon\" aria-hidden=\"true\"><use xlink:href=\"#discourse-expand\"></use></svg>\n</div></a></div></p>
```
`PostSearchData#raw_data` Before:
```
This is a test topic 0 Uncategorized Let me see how I can fix this image some.png png https://meta.discourse.org/some.png discourse org/some png some.png png 1750×2000
```
`PostSearchData#raw_data` After:
```
This is a test topic 0 Uncategorized Let me see how I can fix this image
```
In terms of indexing performance, we now have to parse the given HTML
through nokogiri twice. However performance is not a huge worry here since a string length of 194170 takes only 30ms
to scrub plus the indexing takes place in a background job.
Includes support for flags, reviewable users and queued posts, with REST API
backwards compatibility.
Co-Authored-By: romanrizzi <romanalejandro@gmail.com>
Co-Authored-By: jjaffeux <j.jaffeux@gmail.com>
- s3_force_path_style was added as a Minio specific url scheme but it has never been well supported in our code base.
- Our new migrate_to_s3 rake task does not work reliably with path style urls too
- Minio has also added support for virtual style requests i.e the same scheme as AWS S3/DO Spaces so we can rely on that instead of using path style requests.
- Add migration to drop s3_force_path_style from the site_settings table
* improved emoji support
- always optimize images as part of the task
- use the unicode standard ordering/naming for sections
* UX: more height for when there are recently used
Migrates email user options to a new data structure, where `email_always`, `email_direct` and `email_private_messages` are replace by
* `email_messages_level`, with options: `always`, `only_when_away` and `never` (defaults to `always`)
* `email_level`, with options: `always`, `only_when_away` and `never` (defaults to `only_when_away`)
* FEATURE: Exposing a way to add a generic report filter
## Why do we need this change?
Part of the work discussed [here](https://meta.discourse.org/t/gain-understanding-of-file-uploads-usage/104994), and implemented a first spike [here](https://github.com/discourse/discourse/pull/6809), I am trying to expose a single generic filter selector per report.
## How does this work?
We basically expose a simple, single generic filter that is computed and displayed based on backend values passed into the report.
This would be a simple contract between the frontend and the backend.
**Backend changes:** we simply need to return a list of dropdown / select options, and enable the report's newly introduced `custom_filtering` property.
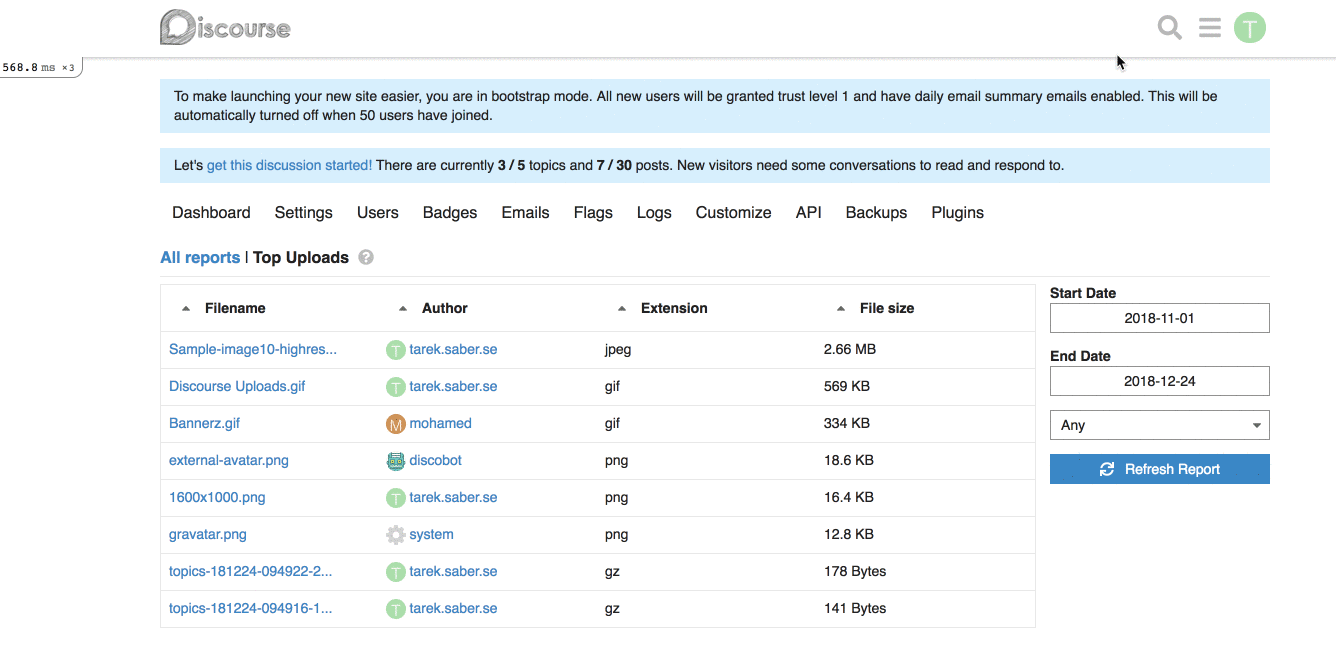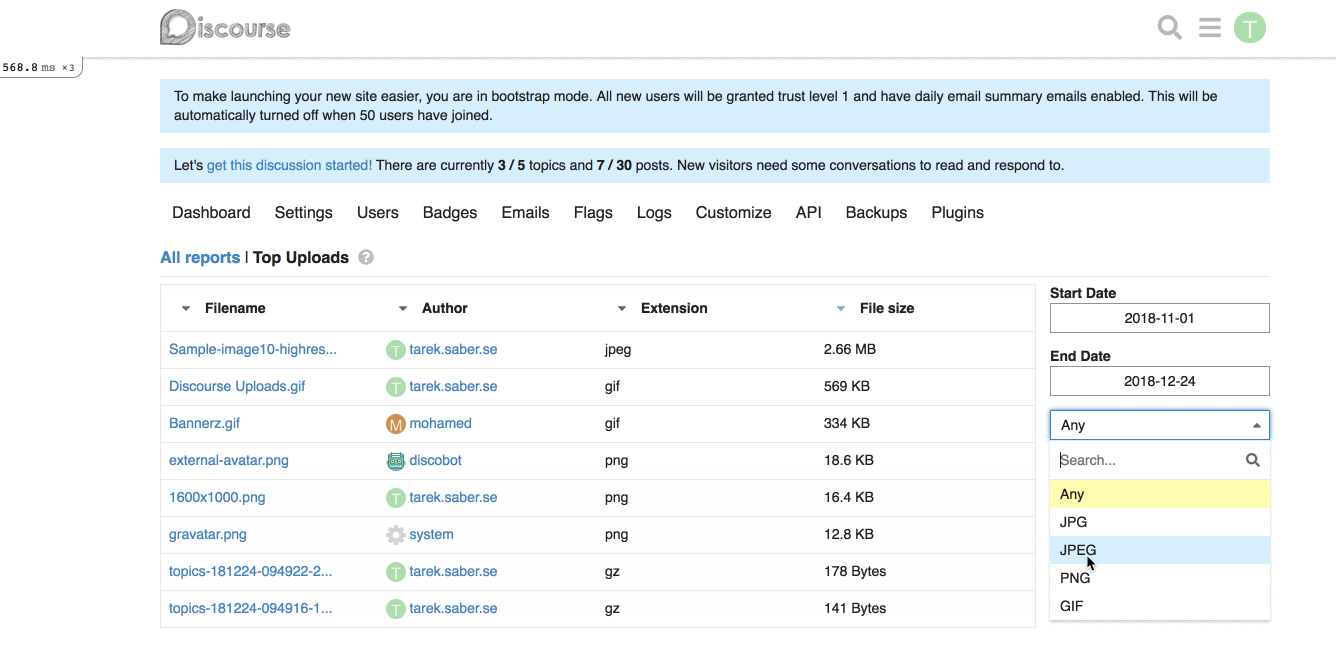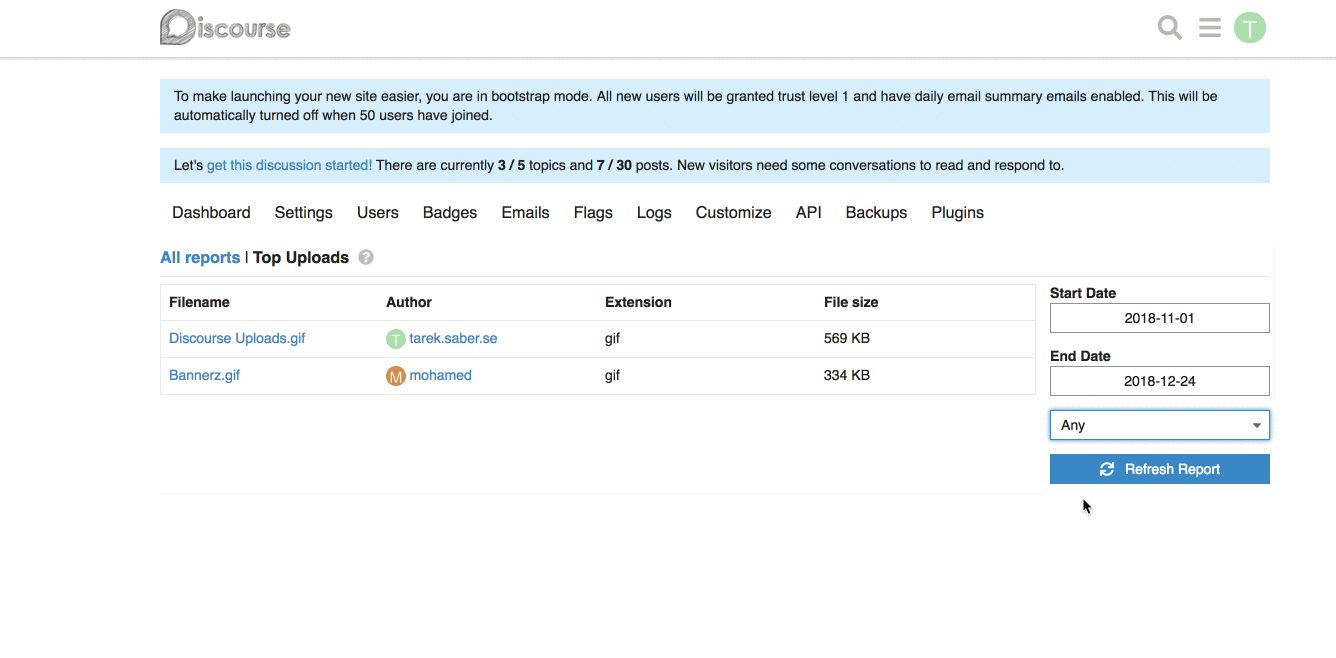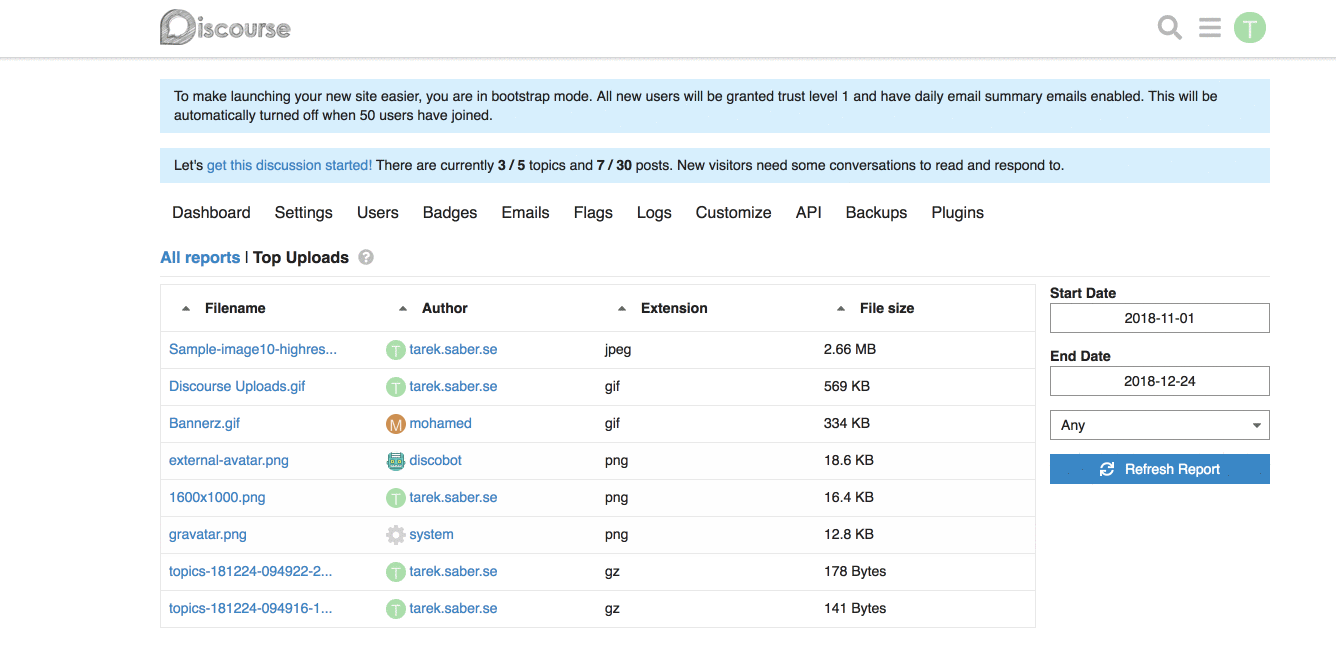
For example, for our [Top Uploads](https://github.com/discourse/discourse/pull/6809/files#diff-3f97cbb8726f3310e0b0c386dbe89e22R1423) report, it can look like this on the backend:
```ruby
report.custom_filtering = true
report.custom_filter_options = [{ id: "any", name: "Any" }, { id: "jpg", name: "JPEG" } ]
```
In our javascript report HTTP call, it will look like:
```js
{
"custom_filtering": true,
"custom_filter_options": [
{
"id": "any",
"name": "Any"
},
{
"id": "jpg",
"name": "JPG"
}
]
}
```
**Frontend changes:** We introduced a generic `filter` param and a `combo-box` which hooks up into the existing framework for fetching a report.
This works alright, with the limitation of being a single custom filter per report. If we wanted to add, for an instance a `filesize filter`, this will not work for us. _I went through with this approach because it is hard to predict and build abstractions for requirements or problems we don't have yet, or might not have._
## How does it look like?
## More on the bigger picture
The major concern here I have is the solution I introduced might serve the `think small` version of the reporting work, but I don't think it serves the `think big`, I will try to shed some light into why.
Within the current design, It is hard to maintain QueryParams for dynamically generated params (based on the idea of introducing more than one custom filter per report).
To allow ourselves to have more than one generic filter, we will need to:
a. Use the Route's model to retrieve the report's payload (we are now dependent on changes of the QueryParams via computed properties)
b. After retrieving the payload, we can use the `setupController` to define our dynamic QueryParams based on the custom filters definitions we received from the backend
c. Load a custom filter specific Ember component based on the definitions we received from the backend
* First take
* Add support for sprites in themes
Automatically register any custom icons added via themes or plugins
* Fix theme sprite caching
* Simplify test
* Update lib/svg_sprite/svg_sprite.rb
Co-Authored-By: pmusaraj <pmusaraj@gmail.com>
* Fix /svg-sprite/search request
* FEATURE: Add `Top Ignored Users` report
## Why?
This is part of the [Ability to ignore a user feature](https://meta.discourse.org/t/ability-to-ignore-a-user/110254/8), and also part of [this PR](https://github.com/discourse/discourse/pull/7144).
We want to send a System Message daily when a specific count threshold for an ignored is reached. To make this system message informative, we want to link to a report for the Top Ignored Users too.
- Notices are visible only by poster and trust level 2+ users.
- Notices are not generated for non-human or staged users.
- Notices are deleted when post is deleted.
It seems that due to jobs being asynchronous and wrapping code in a
DistributedMutex that by the time we run the
`UserAvatar#update_gravatar!` job that the user/user email might be
destroyed.
This patch checks before a call to `user.email_hash` to make sure
the user and primary email exist to prevent the exception. If not
present, the job exits as there's nothing to do because we are
probably running after the user was destroyed for some reason.
{kind=link}
{kind=link}