Adds a report to show the top 100 most viewed topics in a date range,
combining logged in and anonymous views. Can be filtered by category.
This is a followup to 527f02e99f
and d1191b7f5f. We are also going to
be able to see this data in a new topic map, but this admin report
helps to see an overview across the forum for a date range.
Followup 2f2da72747
When the "Consolidated Pageviews with Browser Detection (Experimental)"
report was introduced, we started counting the original
"page_view_logged_in" and "page_view_anon" ApplicationRequest
data as "Other Pageviews", subtracting
"page_view_anon_browser" and "page_view_logged_in_browser" from
this number.
However we unknowingly automatically started counting these
browser-based page views, which are a subset of the total
"page_view_logged_in" and "page_view_anon" counts, in the
original "Pageviews" report, leading to double counting
which meant that when you looked at the data for each
report side-by-side the data didn't add up.
This commit fixes the issue by not counting the "browser"
pageviews in the Pageviews report, and making the code where
we were only counting certain types of requests for this
report more plain, explicitly stating which types of requests
we want.
Followup 94fe31e5b3,
change the color of the "Known Crawler" bar on the
new "Consolidated Pageviews with Browser Detection (Experimental)"
report to be purple, like it was on the original
"Consolidated Pageviews" report to allow for easier
visual comparison.
Also removes the report colors to named keys in a hash
for easier reference than having to look up the
index of the array all the time.
Our 'page_view_crawler' / 'page_view_anon' metrics are based purely on the User Agent sent by clients. This means that 'badly behaved' bots which are imitating real user agents are counted towards 'anon' page views.
This commit introduces a new method of tracking visitors. When an initial HTML request is made, we assume it is a 'non-browser' request (i.e. a bot). Then, once the JS application has booted, we notify the server to count it as a 'browser' request. This reliance on a JavaScript-capable browser matches up more closely to dedicated analytics systems like Google Analytics.
Existing data collection and graphs are unchanged. Data collected via the new technique is available in a new 'experimental' report.
We added support for radar type charts in #24274. However, radar charts work with three variables, meaning we can't display any report that way.
Unfortunately, by adding `:radar` to the `Report#modes` variable, I made them widely available.
Related bug report: https://meta.discourse.org/t/report-radar-graph-uncaught-typeerror/292360
Adding a filter without a type parameter has been deprecated for the last three years, and was marked for removal in 2.9.0.
During this time we have had a few deprecation warnings in logs coming from Reports::Bookmarks.
The fallback was to set the type to the name of the filter. This change just passes the type (same as name) explicitly instead, and removes the deprecation fallback.
Adds stats for API and user API requests similar to regular page views.
This comes with a new report to visualize API requests per day like the
consolidated page views one.
This is a bottom up rewrite of Discourse cache to support faster performance
and a limited surface area.
ActiveSupport::Cache::Store accepts many options we do not use, this partial
implementation only picks the bits out that we do use and want to support.
Additionally params are named which avoids typos such as "expires_at" vs "expires_in"
This also moves a few spots in Discourse to use Discourse.cache over setex
Performance of setex and Discourse.cache.write is similar.
Zeitwerk simplifies working with dependencies in dev and makes it easier reloading class chains.
We no longer need to use Rails "require_dependency" anywhere and instead can just use standard
Ruby patterns to require files.
This is a far reaching change and we expect some followups here.
This reduces chances of errors where consumers of strings mutate inputs
and reduces memory usage of the app.
Test suite passes now, but there may be some stuff left, so we will run
a few sites on a branch prior to merging
If you turn it on now, default all users to approved since they were
previously. Also support approving a user that doesn't have a reviewable
record (it will be created first.)
This also includes a refactor to move class method calls to
`DiscourseEvent` into an initializer. Otherwise the load order of
classes makes a difference in the test environment and some settings
might be triggered and others not, randomly.
Includes support for flags, reviewable users and queued posts, with REST API
backwards compatibility.
Co-Authored-By: romanrizzi <romanalejandro@gmail.com>
Co-Authored-By: jjaffeux <j.jaffeux@gmail.com>
* FEATURE: Exposing a way to add a generic report filter
## Why do we need this change?
Part of the work discussed [here](https://meta.discourse.org/t/gain-understanding-of-file-uploads-usage/104994), and implemented a first spike [here](https://github.com/discourse/discourse/pull/6809), I am trying to expose a single generic filter selector per report.
## How does this work?
We basically expose a simple, single generic filter that is computed and displayed based on backend values passed into the report.
This would be a simple contract between the frontend and the backend.
**Backend changes:** we simply need to return a list of dropdown / select options, and enable the report's newly introduced `custom_filtering` property.
For example, for our [Top Uploads](https://github.com/discourse/discourse/pull/6809/files#diff-3f97cbb8726f3310e0b0c386dbe89e22R1423) report, it can look like this on the backend:
```ruby
report.custom_filtering = true
report.custom_filter_options = [{ id: "any", name: "Any" }, { id: "jpg", name: "JPEG" } ]
```
In our javascript report HTTP call, it will look like:
```js
{
"custom_filtering": true,
"custom_filter_options": [
{
"id": "any",
"name": "Any"
},
{
"id": "jpg",
"name": "JPG"
}
]
}
```
**Frontend changes:** We introduced a generic `filter` param and a `combo-box` which hooks up into the existing framework for fetching a report.
This works alright, with the limitation of being a single custom filter per report. If we wanted to add, for an instance a `filesize filter`, this will not work for us. _I went through with this approach because it is hard to predict and build abstractions for requirements or problems we don't have yet, or might not have._
## How does it look like?
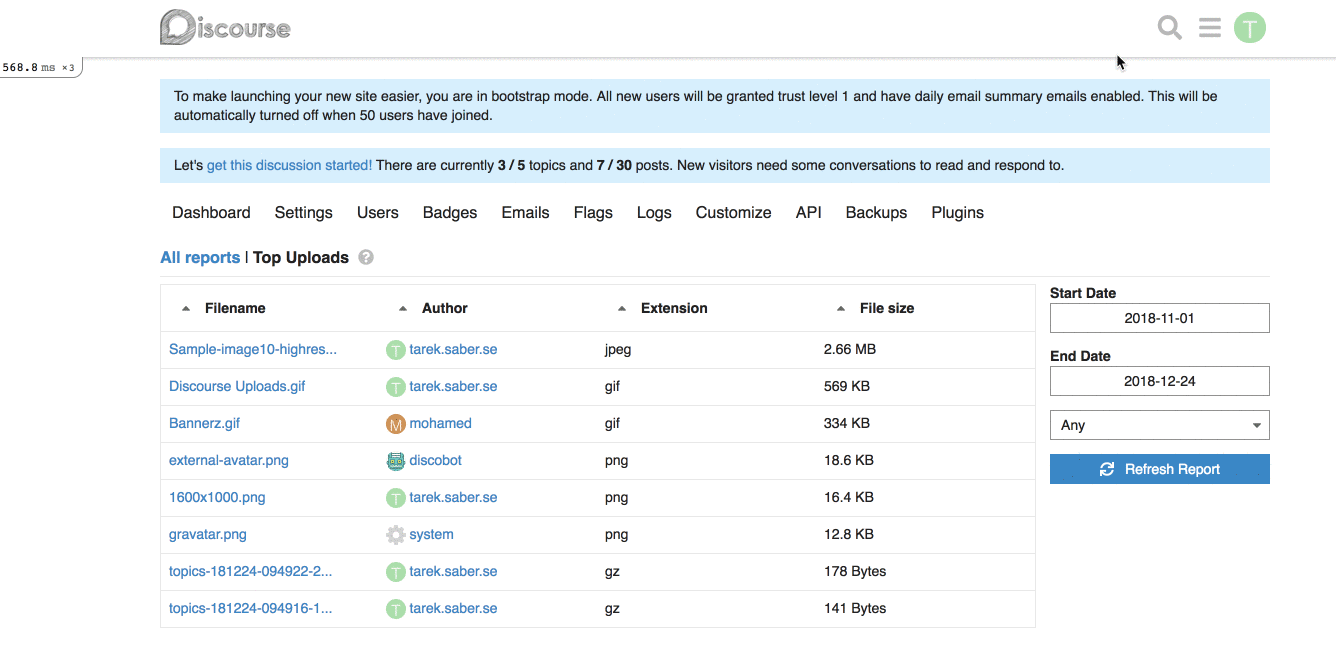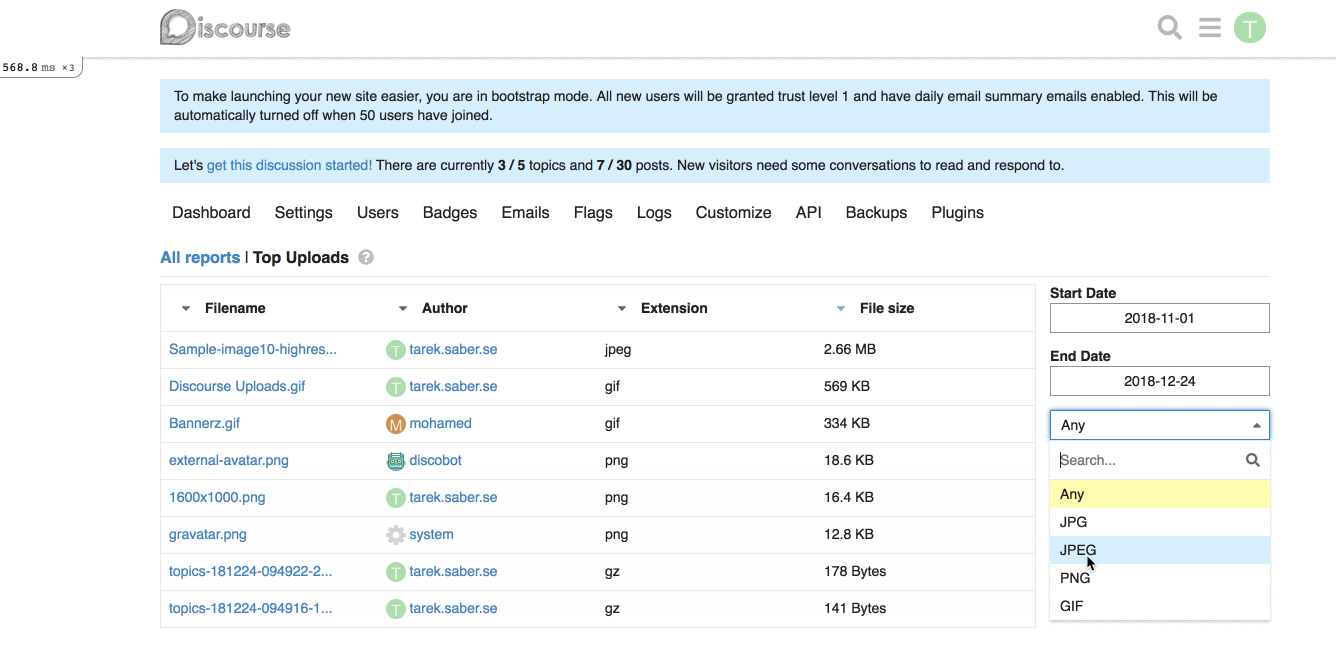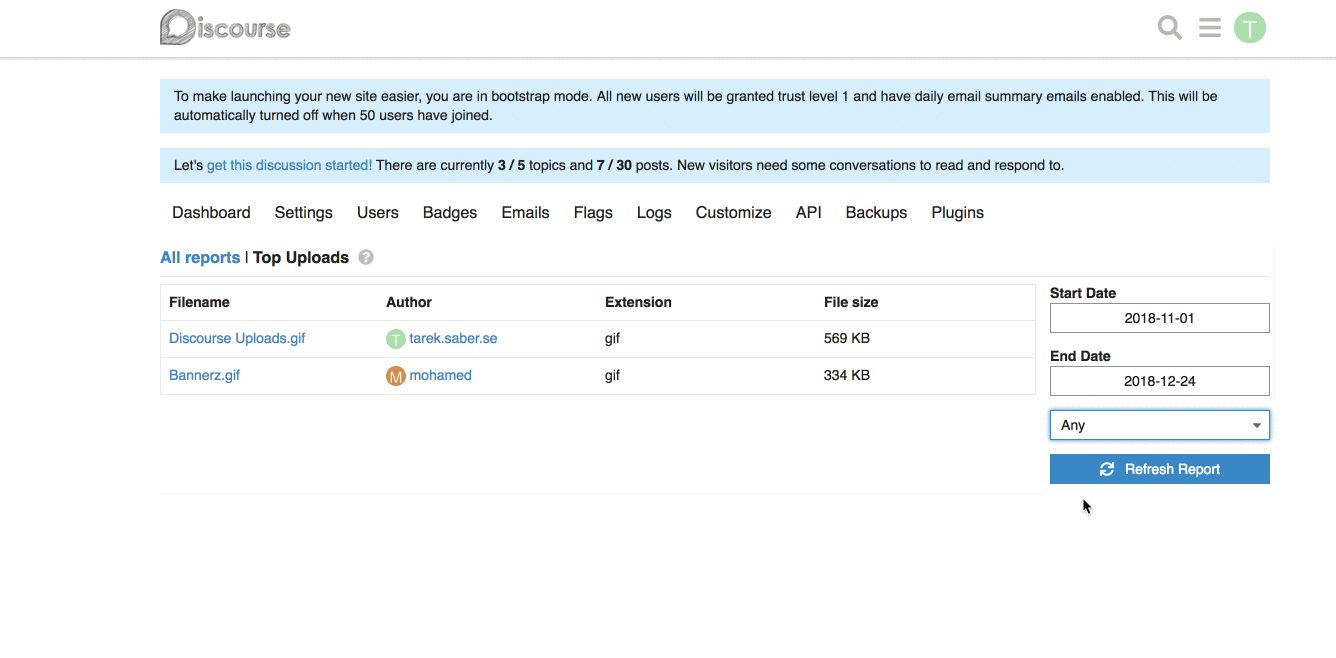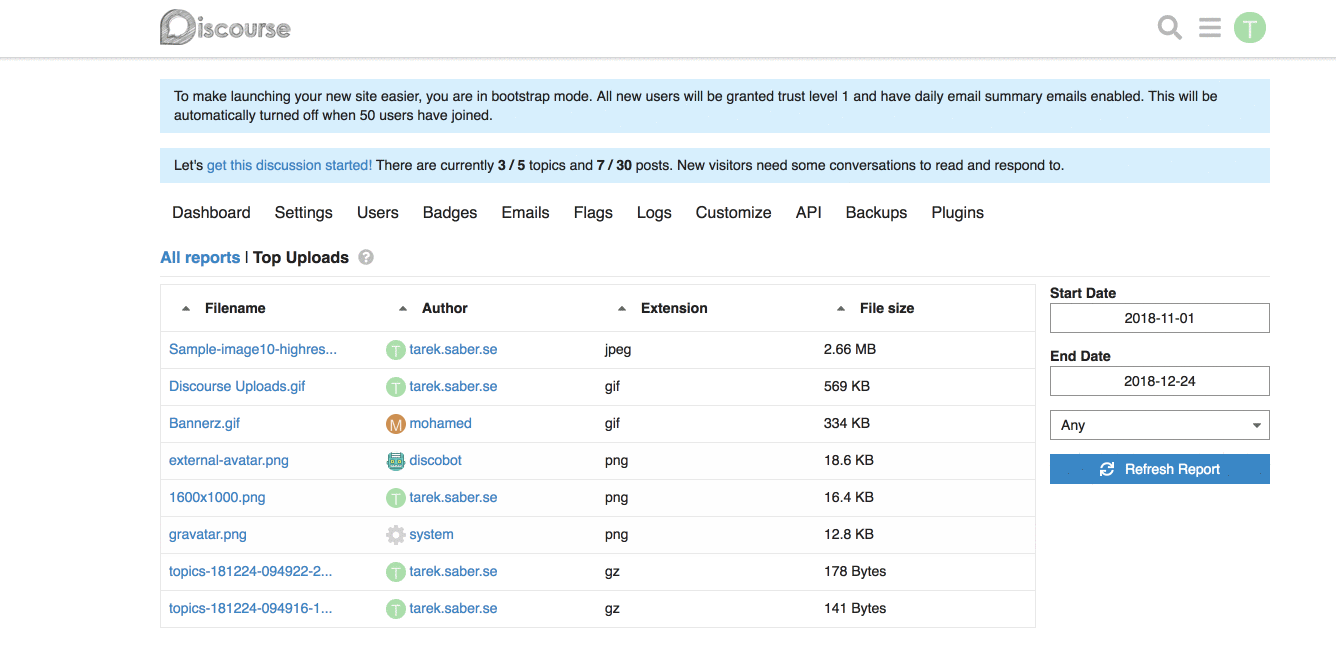
## More on the bigger picture
The major concern here I have is the solution I introduced might serve the `think small` version of the reporting work, but I don't think it serves the `think big`, I will try to shed some light into why.
Within the current design, It is hard to maintain QueryParams for dynamically generated params (based on the idea of introducing more than one custom filter per report).
To allow ourselves to have more than one generic filter, we will need to:
a. Use the Route's model to retrieve the report's payload (we are now dependent on changes of the QueryParams via computed properties)
b. After retrieving the payload, we can use the `setupController` to define our dynamic QueryParams based on the custom filters definitions we received from the backend
c. Load a custom filter specific Ember component based on the definitions we received from the backend
* FEATURE: Add `Top Ignored Users` report
## Why?
This is part of the [Ability to ignore a user feature](https://meta.discourse.org/t/ability-to-ignore-a-user/110254/8), and also part of [this PR](https://github.com/discourse/discourse/pull/7144).
We want to send a System Message daily when a specific count threshold for an ignored is reached. To make this system message informative, we want to link to a report for the Top Ignored Users too.
{kind=link}