This reverts commit d1c4981f65.
Per discussion with @coding-horror it was decided this change is to
far reaching.
Instead we will make smaller strategic changes to tooltips that add
value.
* improved emoji support
- always optimize images as part of the task
- use the unicode standard ordering/naming for sections
* UX: more height for when there are recently used
Migrates email user options to a new data structure, where `email_always`, `email_direct` and `email_private_messages` are replace by
* `email_messages_level`, with options: `always`, `only_when_away` and `never` (defaults to `always`)
* `email_level`, with options: `always`, `only_when_away` and `never` (defaults to `only_when_away`)
* FEATURE: Exposing a way to add a generic report filter
## Why do we need this change?
Part of the work discussed [here](https://meta.discourse.org/t/gain-understanding-of-file-uploads-usage/104994), and implemented a first spike [here](https://github.com/discourse/discourse/pull/6809), I am trying to expose a single generic filter selector per report.
## How does this work?
We basically expose a simple, single generic filter that is computed and displayed based on backend values passed into the report.
This would be a simple contract between the frontend and the backend.
**Backend changes:** we simply need to return a list of dropdown / select options, and enable the report's newly introduced `custom_filtering` property.
For example, for our [Top Uploads](https://github.com/discourse/discourse/pull/6809/files#diff-3f97cbb8726f3310e0b0c386dbe89e22R1423) report, it can look like this on the backend:
```ruby
report.custom_filtering = true
report.custom_filter_options = [{ id: "any", name: "Any" }, { id: "jpg", name: "JPEG" } ]
```
In our javascript report HTTP call, it will look like:
```js
{
"custom_filtering": true,
"custom_filter_options": [
{
"id": "any",
"name": "Any"
},
{
"id": "jpg",
"name": "JPG"
}
]
}
```
**Frontend changes:** We introduced a generic `filter` param and a `combo-box` which hooks up into the existing framework for fetching a report.
This works alright, with the limitation of being a single custom filter per report. If we wanted to add, for an instance a `filesize filter`, this will not work for us. _I went through with this approach because it is hard to predict and build abstractions for requirements or problems we don't have yet, or might not have._
## How does it look like?
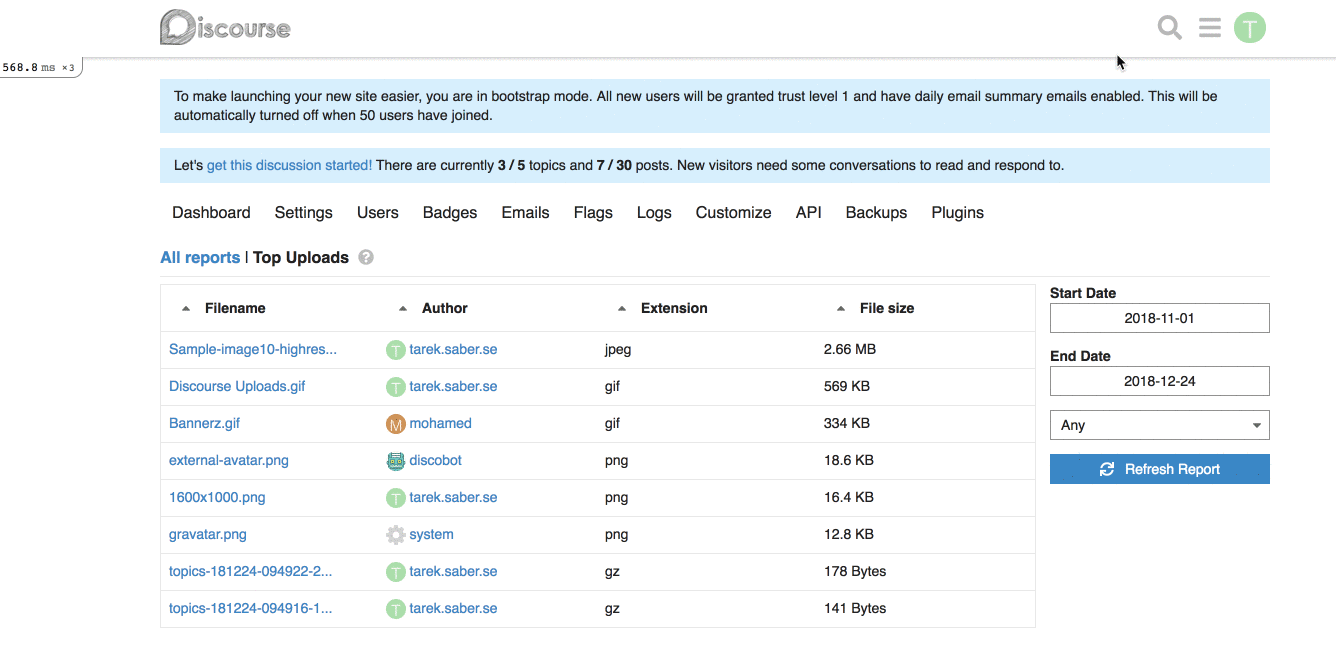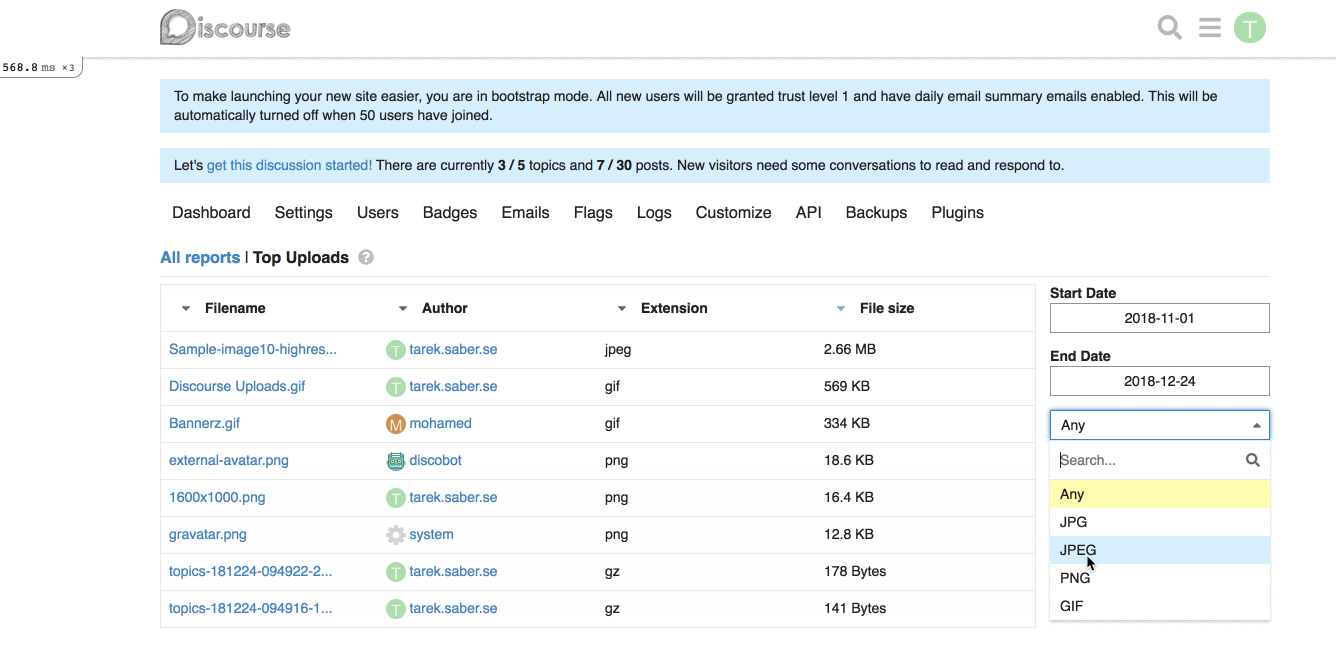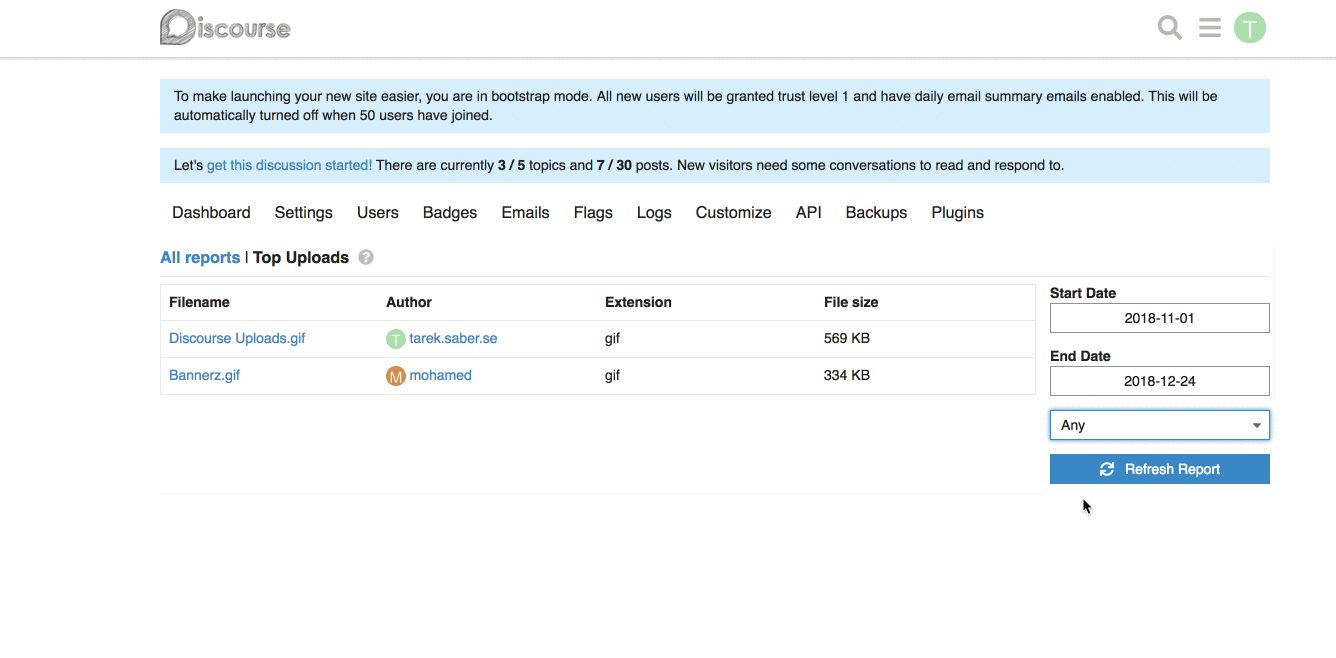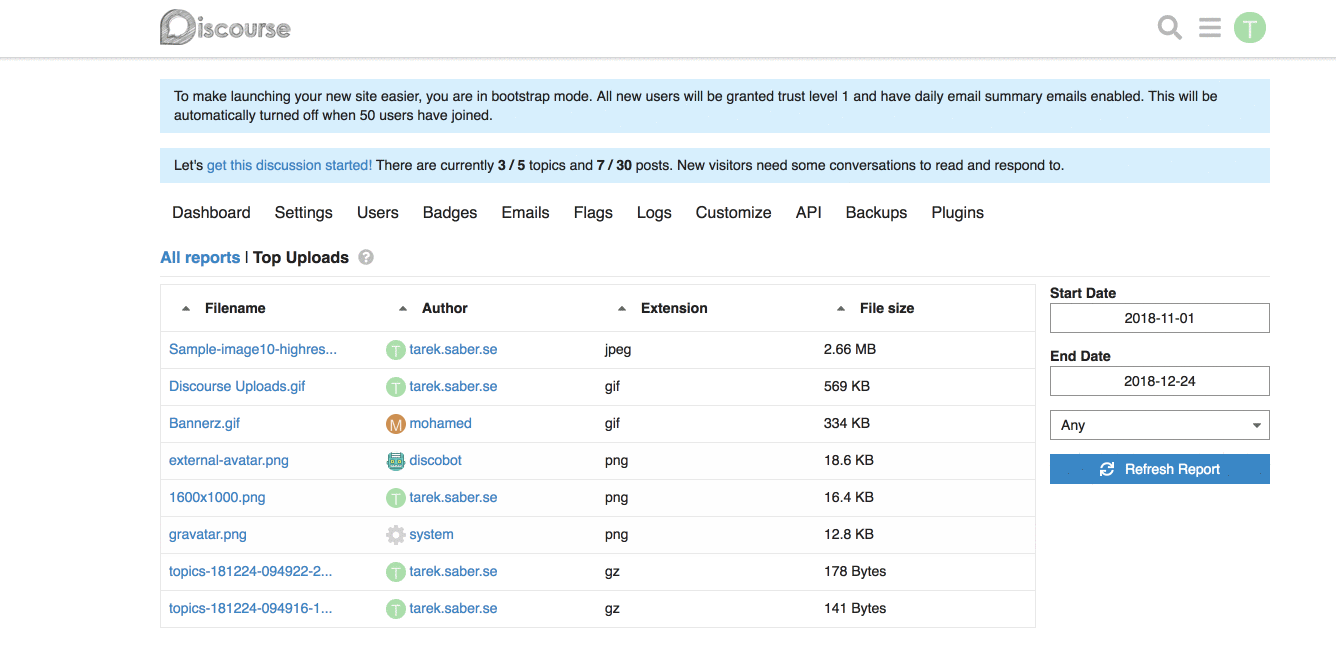
## More on the bigger picture
The major concern here I have is the solution I introduced might serve the `think small` version of the reporting work, but I don't think it serves the `think big`, I will try to shed some light into why.
Within the current design, It is hard to maintain QueryParams for dynamically generated params (based on the idea of introducing more than one custom filter per report).
To allow ourselves to have more than one generic filter, we will need to:
a. Use the Route's model to retrieve the report's payload (we are now dependent on changes of the QueryParams via computed properties)
b. After retrieving the payload, we can use the `setupController` to define our dynamic QueryParams based on the custom filters definitions we received from the backend
c. Load a custom filter specific Ember component based on the definitions we received from the backend
* FEATURE: Add `IgnoredUsersSummary` daily job
## Why?
This is part of the [Ability to ignore a user feature](https://meta.discourse.org/t/ability-to-ignore-a-user/110254/8).
We want to:
1. Send an automatic group PM that goes out to moderators
2. When {x} users have Ignored the same user, threshold defined by a site setting, default of 5
3. Only send this message every X days which is defined by another site setting
It is not a setting, and only relevant in specs. The new API is:
```
Jobs.run_later! # jobs will be thrown on the queue
Jobs.run_immediately! # jobs will run right away, avoid the queue
```
* FEATURE: Add `Top Ignored Users` report
## Why?
This is part of the [Ability to ignore a user feature](https://meta.discourse.org/t/ability-to-ignore-a-user/110254/8), and also part of [this PR](https://github.com/discourse/discourse/pull/7144).
We want to send a System Message daily when a specific count threshold for an ignored is reached. To make this system message informative, we want to link to a report for the Top Ignored Users too.
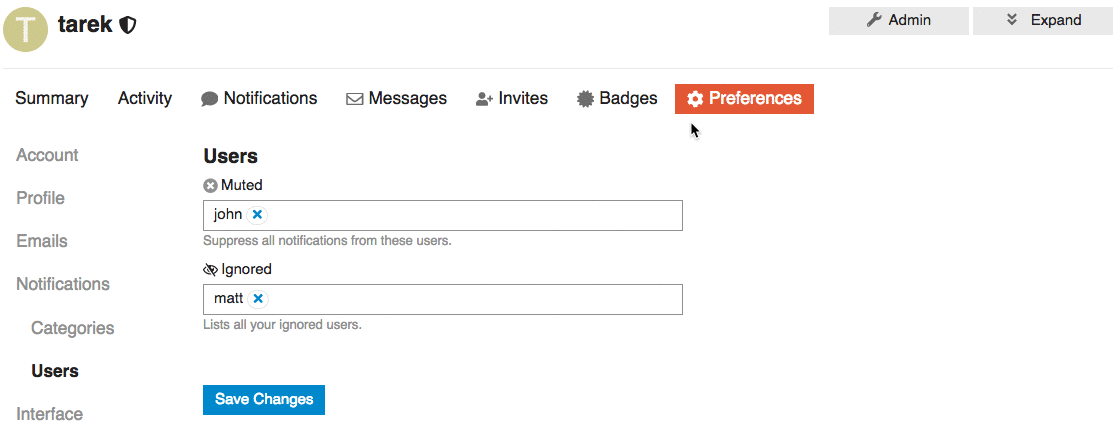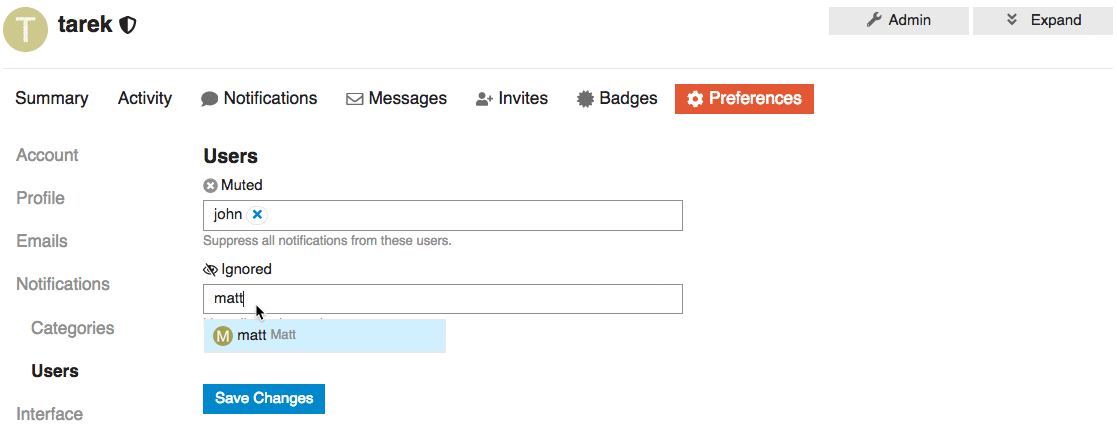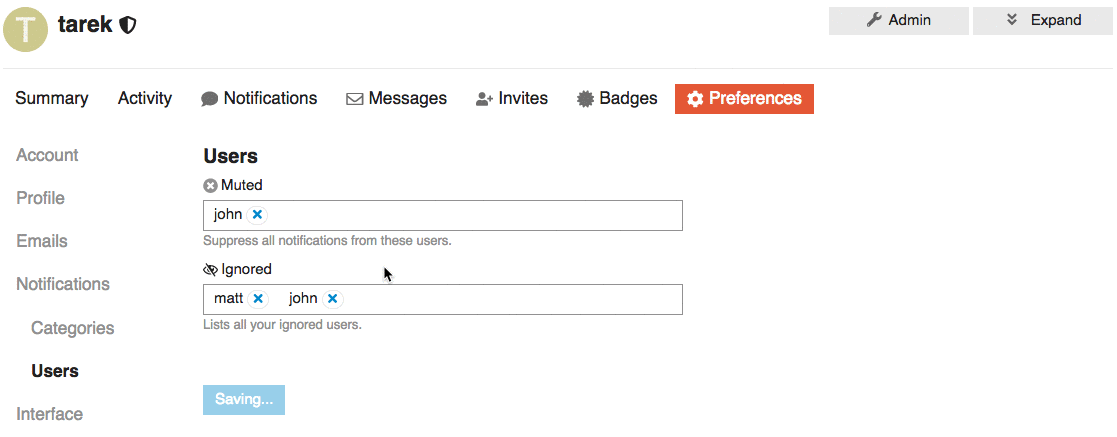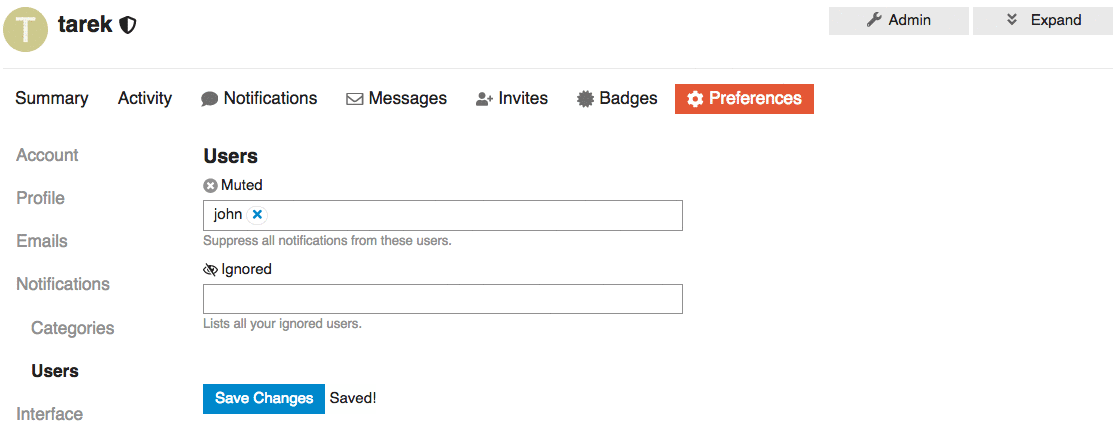
* FEATURE: Add ignored user list to the User's preference page
## Why?
Part of: https://meta.discourse.org/t/ability-to-ignore-a-user/110254
We want to add list of Ignored users under or along with the muted users preferences section.
This way Users can find and update their list of ignored users.
## UI
## Open questions
Two of many options to represent a list of ignored users is that we can:
1. We can represent the ignored user list as a table with the ability to `un-ignore` but NOT to add new ignored users.
2. We can keep it functioning as the `muted user list` where you can `un-ignore` or `ignore` users.
* Adds warnings to the "Edit Category" dialog
* Doesn't hide the "Security" tab on the "Edit Category" dialog anymore. Instead, it shows an explanation why permissions can't be changed.
* Makes the category name translatable
* Hides the category name from the edit dialog (it can be customized by overriding the translation)
* Creates a translation override if the category has been renamed in the past
Sadly there is no clean way of detecting a keyboard is connected to an iPad
If the keyboard is connected we want to disable all the touch related hacks
on iOS
This allows iPad users to specify they have a keyboard connected. Setting
is per device.
Ruby 2.5.3 has an upatched issue that crashes unicorn after fork:
https://bugs.ruby-lang.org/issues/14634
This will be patched in 2.5.4 however for now just warn people dev is slower
and disable async logging on the older rubies
This commit also:
- removes [+ New Topic] behaviour from share, this feature has been duplicated in composer actions, months ago
- introduces our new experimental spacing standard for css: eg: `s(2)`
- introduces a new panel UI for modals
- These advanced fields are hidden behind an 'advanced' button, so will not affect normal use
- The editor has been refactored into a component, and styling cleaned up so menu items do not overlap on small screens
- Styling has been added to indicate which fields are in use for a theme
- Icons have been added to identify which fields have errors
Co-authored-by: Sam Saffron <sam.saffron@gmail.com>
Co-authored-by: David Taylor <david@taylorhq.com>
This gives more control over the request. In particular we can easily
lookup DNS dynamically, instead of only upon NGINX startup.
Previously, NGINX was looking up IP for the letter avatar service and
caching the CDN IP address, this caused issues if CDN changed IP, in
which letter avatars would be broken till a container restarted.
NGINX config has been updated to add caching. This change will require
a container rebuild.
The proxy will now function in development environments, so the patch
for `letter_avatar_proxy` has been removed.
This makes backups slimmer out of the box but introduces extra process post
restore to run a full rebake of all posts containing uploads and all avatars
The benefit (slimmer backup) outweighs the cost of running the full rebake
`rails/all` includes too much stuff per: https://github.com/rails/rails/blob/master/railties/lib/rails/all.rb
This commit makes it explicit what pieces of Rails Discourse depends on.
Previously the LoadError was protecting us and we were excluding components,
using the Gemfile, this method ensures that even if we add `rails` meta gem
as a dependency only the parts of Rails Discourse uses will be used.
New `about.json` fields (all optional):
- `authors`: An arbitrary string describing the theme authors
- `theme_version`: An arbitrary string describing the theme version
- `minimum_discourse_version`: Theme will be auto-disabled for lower versions. Must be a valid version descriptor.
- `maximum_discourse_version`: Theme will be auto-disabled for lower versions. Must be a valid version descriptor.
A localized description for a theme can be provided in the language files under the `theme_metadata.description` key
The admin UI has been re-arranged to display this new information, and give more prominence to the remote theme options.
We had Prettier pinned because of https://github.com/prettier/prettier/issues/5529. Since that bug is fixed, unpinning.
Prettier now supports YAML, so this applies Prettier to all .yml except for translations, which should not be edited directly anyway.
- Themes can supply translation files in a format like `/locales/{locale}.yml`. These files should be valid YAML, with a single top level key equal to the locale being defined. For now these can only be defined using the `discourse_theme` CLI, importing a `.tar.gz`, or from a GIT repository.
- Fallback is handled on a global level (if the locale is not defined in the theme), as well as on individual keys (if some keys are missing from the selected interface language).
- Administrators can override individual keys on a per-theme basis in the /admin/customize/themes user interface.
- Theme developers should access defined translations using the new theme prefix variables:
JavaScript: `I18n.t(themePrefix("my_translation_key"))`
Handlebars: `{{theme-i18n "my_translation_key"}}` or `{{i18n (theme-prefix "my_translation_key")}}`
- To design for backwards compatibility, theme developers can check for the presence of the `themePrefix` variable in JavaScript
- As part of this, the old `{{themeSetting.setting_name}}` syntax is deprecated in favour of `{{theme-setting "setting_name"}}`
On the first migration, trying to access the users table will throw an
error in PostgreSQL's log which has been confusing since users will
report it to us when rebuild fails.
* UX: Improve logo setting texts to hint that dimensions are a requirement
follow-up on 67a7670b
Use 512 × 512 instead of 512 x 512 or 512 by 512
* UX: Normalize all SiteSetting text dimensions to use the '512 × 512' format
This commit introduces an ultra low priority queue for post rebakes. This
way rebakes can never interfere with regular sidekiq processing for cases
where we perform a large scale rebake.
Additionally it allows Post.rebake_old to be run with rate_limiter: false
to avoid triggering the limiter when rebaking. This is handy for cases
where you want to just force the full rebake and not wait for it to trickle
The locale key had to be renamed, because this key is also used as CSS class.
The "invisible" CSS class makes the icon invisible. "unlisted" doesn't have that effect.
- adds migration to enable CSP for new sites
- removes "EXPERIMENTAL" labels from setting names
- sets CSP violation report to default off
- adds CSP-related note to GTM setting
Regression following the ember3 upgrade. In addition to fixing, this commit consolidates our social registration logic into one place, and adds tests for the behaviour.
Some cloud providers (Google Memorystore) do not support any CLIENT commands
By setting :id to nil in the redis config hash we can avoid these commands.
This adds a special global setting GCE users can enable:
`DISCOURSE_REDIS_SKIP_CLIENT_COMMANDS = true`
This is a possible solution for https://meta.discourse.org/t/user-api-keys-specification/48536/19
This allows for user-api-key requests to not require a redirect url.
Instead, the encypted payload will just be displayed after creation ( which can be copied
pasted into an env for a CLI, for example )
Also: Show instructions when creating user-api-key w/out redirect
This adds a view to show instructions when requesting a user-api-key
without a redirect. It adds a erb template and json format.
Also adds a i18n user_api_key.instructions for server.en.yml
We have the periodical job that regularly will rebake old posts. This is
used to trickle in update to cooked markdown. The problem is that each rebake
can issue multiple background jobs (post process and pull hotlinked images)
Previously we had no per-cluster limit so cluster running 100s of sites could
flood the sidekiq queue with rebake related jobs.
New system introduces a hard limit of 300 rebakes per 15 minutes across a
cluster to ensure the sidekiq job is not dominated by this.
We also reduced `rebake_old_posts_count` to 80, which is a safer default.
This avoids require dependency on method_profiler and anon cache.
It means that if there is any change to these files the reloader will not pick it up.
Previously the reloader was picking up the anon cache twice causing it to double load on boot.
This caused warnings.
Long term my plan is to give up on require dependency and instead use:
https://github.com/Shopify/autoload_reloader
This validation makes sure that the s3_upload_bucket and the
s3_backup_bucket have different values. The backup bucket is
allowed to be a subfolder of the upload bucket. The other way
around is forbidden because the backup system searches by
prefix and would return all files stored within the backup
bucket and its subfolders.
* Dashboard doesn't timeout anymore when Amazon S3 is used for backups
* Storage stats are now a proper report with the same caching rules
* Changing the backup_location, s3_backup_bucket or creating and deleting backups removes the report from the cache
* It shows the number of backups and the backup location
* It shows the used space for the correct backup location instead of always showing used space on local storage
* It shows the date of the last backup as relative date
This provides us with instrumentation missing after rails upgrade
Latest version of rails uses exec_params internally which is no longer
routed to intercepted methods in mini profiler 1.0.0
The wizard searches for:
* a topic that with the "is_welcome_topic" custom field
* a topic with the correct slug for the current default locale
* a topic with the correct slug for the English locale
* the oldest globally pinned topic
It gives up if it didn't find any of the above.
{kind=link}
{kind=link}